
前言
之前每日一题的markdown文件不知道哪去了,只能重新开始写,以后记得备份文件!
记录本人力扣每日一题的思路,如果日期后面有补字,则代表当天忘了做,后面补上的
本来想弄个目录的,但是 Typora 自动生成目录又会带上题目、思路和代码这样的小题目,而且单一个日期好像也没什么用,想了想还是算了,毕竟如果要自己手动维护一个目录很麻烦,而且如果真的想针对性的找什么内容,使用Ctrl + f就可以直接搜索了。
2021/5/16
题目
难度中等274收藏分享切换为英文接收动态反馈
给你一个整数数组 nums ,返回 nums[i] XOR nums[j] 的最大运算结果,其中 0 ≤ i ≤ j < n 。
进阶:你可以在 O(n) 的时间解决这个问题吗?
示例 1:
1 | 输入:nums = [3,10,5,25,2,8] |
示例 2:
1 | 输入:nums = [0] |
示例 3:
1 | 输入:nums = [2,4] |
示例 4:
1 | 输入:nums = [8,10,2] |
示例 5:
1 | 输入:nums = [14,70,53,83,49,91,36,80,92,51,66,70] |
提示:
1 <= nums.length <= 2 * 1040 <= nums[i] <= 231 - 1
思路
暴力就不说了,没想到不暴力的解法如此麻烦。
从最高位开始,枚举每一位能否取到1,如果可以的话,将这个标为答案(贪心的思想),就这样一直标下去,最后返回答案。为了优化,将数字存入 Hash 里面,以便查询,更具体的看代码,这一次贴的是 Java 的代码
代码
1 | class Solution { |
2021/5/15
题目
难度简单1320收藏分享切换为英文接收动态反馈
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 | 字符 数值 |
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1:
1 | 输入: "III" |
示例 2:
1 | 输入: "IV" |
示例 3:
1 | 输入: "IX" |
示例 4:
1 | 输入: "LVIII" |
示例 5:
1 | 输入: "MCMXCIV" |
提示:
1 <= s.length <= 15s仅含字符('I', 'V', 'X', 'L', 'C', 'D', 'M')- 题目数据保证
s是一个有效的罗马数字,且表示整数在范围[1, 3999]内 - 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics 。
思路
当小的数字在大的左边的时候,表示减,否则是加
代码
1 | func romanToInt(s string) int { |
2021/5/14
题目
难度中等611收藏分享切换为英文接收动态反馈
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 | 字符 数值 |
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给你一个整数,将其转为罗马数字。
示例 1:
1 | 输入: num = 3 |
示例 2:
1 | 输入: num = 4 |
示例 3:
1 | 输入: num = 9 |
示例 4:
1 | 输入: num = 58 |
示例 5:
1 | 输入: num = 1994 |
提示:
1 <= num <= 3999
思路
模拟,取出每一位,然后根据取出来的位数分情况处理。
看完题解以后,发现这种解法啰嗦了,其实罗马数字本质上就是累加数字,数字的权重都是1,所以直接从最大的数字可以减,减到不能减就下一个数字,直到为0。
第三种,直接得出每一位数字的罗马数字的所有可能组合,然后每一次就可以直接拿
代码
自己的啰嗦代码(这里还有一个需要注意的,因为是从最小的取起,所以需要反转,逻辑处理也需要反转一下)
1 | package main |
第二种
1 | // 可以使用map来代替吧? |
第三种
1 | var ( |
2021/5/10
题目
难度简单125收藏分享切换为英文接收动态反馈
请考虑一棵二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
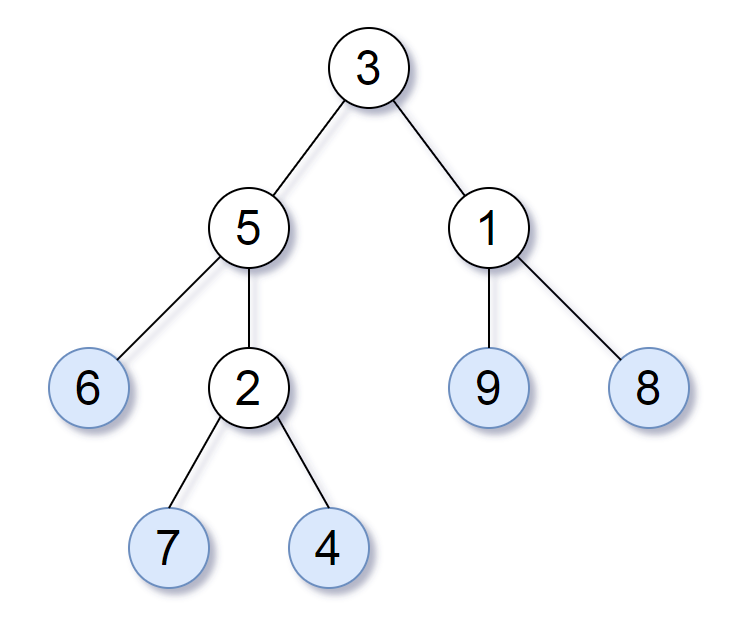
举个例子,如上图所示,给定一棵叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两棵二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
如果给定的两个根结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
示例 1:
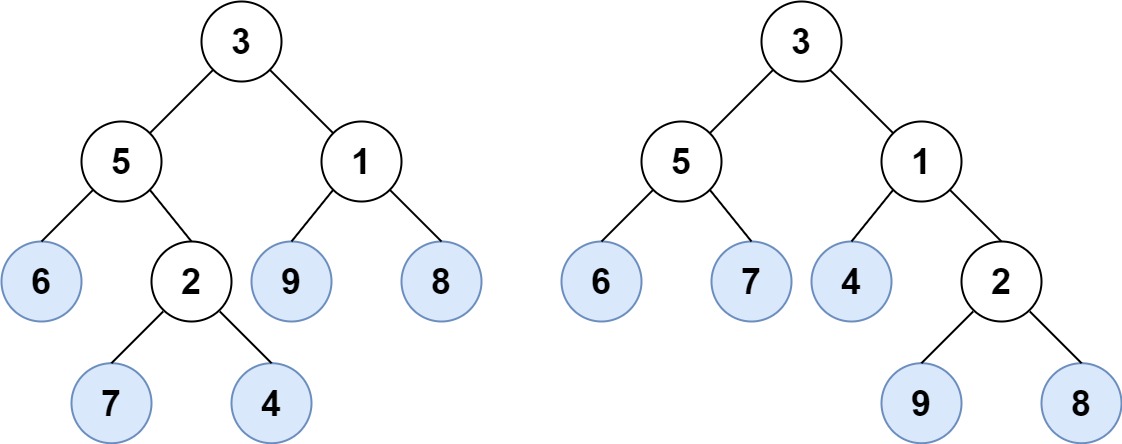
1 | 输入:root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] |
示例 2:
1 | 输入:root1 = [1], root2 = [1] |
示例 3:
1 | 输入:root1 = [1], root2 = [2] |
示例 4:
1 | 输入:root1 = [1,2], root2 = [2,2] |
示例 5:
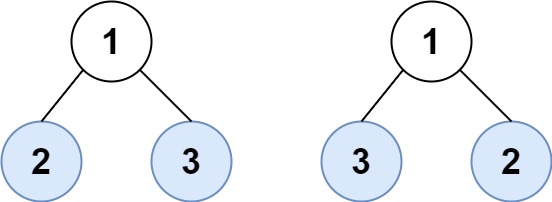
1 | 输入:root1 = [1,2,3], root2 = [1,3,2] |
提示:
- 给定的两棵树可能会有
1到200个结点。 - 给定的两棵树上的值介于
0到200之间。
思路
分别深搜,然后根据搜索的叶子结点顺序进行比较即可
代码
1 | /** |
2021/5/9
题目
难度中等123收藏分享切换为英文接收动态反馈
给你一个整数数组 bloomDay,以及两个整数 m 和 k 。
现需要制作 m 束花。制作花束时,需要使用花园中 相邻的 k 朵花 。
花园中有 n 朵花,第 i 朵花会在 bloomDay[i] 时盛开,恰好 可以用于 一束 花中。
请你返回从花园中摘 m 束花需要等待的最少的天数。如果不能摘到 m 束花则返回 -1 。
示例 1:
1 | 输入:bloomDay = [1,10,3,10,2], m = 3, k = 1 |
示例 2:
1 | 输入:bloomDay = [1,10,3,10,2], m = 3, k = 2 |
示例 3:
1 | 输入:bloomDay = [7,7,7,7,12,7,7], m = 2, k = 3 |
示例 4:
1 | 输入:bloomDay = [1000000000,1000000000], m = 1, k = 1 |
示例 5:
1 | 输入:bloomDay = [1,10,2,9,3,8,4,7,5,6], m = 4, k = 2 |
提示:
bloomDay.length == n1 <= n <= 10^51 <= bloomDay[i] <= 10^91 <= m <= 10^61 <= k <= n
思路
二分,上界是日期最大值,下界是最小值。
注意:go 的 int 有很多个类型,不要用太小的(我一开始用 int8 去统计花的数量,错了)
代码
1 | package main |
其他
对于这种题目,还是很难很快想到使用二分查找,多练练吧
2021/5/7
题目
难度简单57收藏分享切换为英文接收动态反馈
给你两个整数,n 和 start 。
数组 nums 定义为:nums[i] = start + 2*i(下标从 0 开始)且 n == nums.length 。
请返回 nums 中所有元素按位异或(XOR)后得到的结果。
示例 1:
1 | 输入:n = 5, start = 0 |
示例 2:
1 | 输入:n = 4, start = 3 |
示例 3:
1 | 输入:n = 1, start = 7 |
示例 4:
1 | 输入:n = 10, start = 5 |
提示:
1 <= n <= 10000 <= start <= 1000n == nums.length
思路
模拟,没了,我还以为有什么技巧,结果是数学推导
代码
这一次是用 GO 写的
1 | func xorOperation(n int, start int) int { |
其他
摸了一周,十分抱歉
2021/4/28
题目
难度中等203收藏分享切换为英文接收动态反馈
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 + b2 = c 。
示例 1:
1 | 输入:c = 5 |
示例 2:
1 | 输入:c = 3 |
示例 3:
1 | 输入:c = 4 |
示例 4:
1 | 输入:c = 2 |
示例 5:
1 | 输入:c = 1 |
提示:
0 <= c <= 231 - 1
思路
方法一:
根据上界(根号c)以及下界(0),然后遍历这个区间,通过固定一个数来判断另外一个数是否满足条件。
方法二:
双指针,根据上界和下界来进行双指针,如果两个指针指向的数和平方和大于目标,则右指针左移(减少),如果大于则左指针右移(增大)。
代码
方法一
1 | public boolean judgeSquareSum(int c) { |
方法二:
1 | public boolean judgeSquareSum(int c) { |
2021/4/27
题目
难度简单176收藏分享切换为英文接收动态反馈
给定二叉搜索树的根结点 root,返回值位于范围 [low, high] 之间的所有结点的值的和。
示例 1:
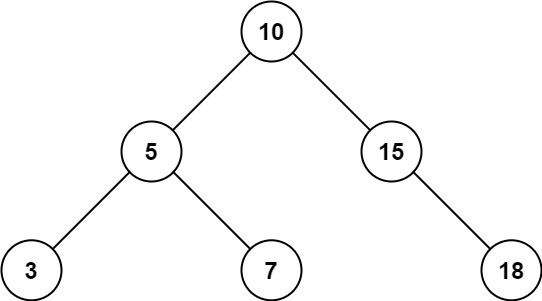
1 | 输入:root = [10,5,15,3,7,null,18], low = 7, high = 15 |
示例 2:
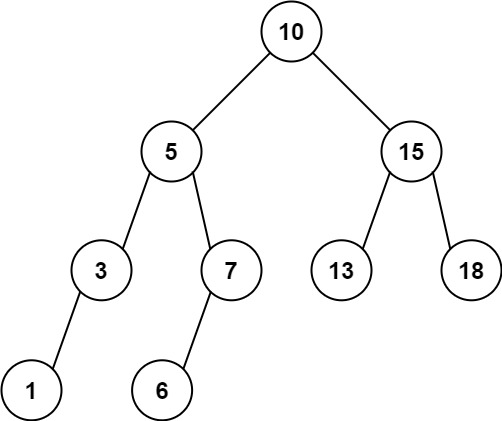
1 | 输入:root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10 |
提示:
- 树中节点数目在范围
[1, 2 * 104]内 1 <= Node.val <= 1051 <= low <= high <= 105- 所有
Node.val互不相同
思路
其实就是搜,根据二叉搜索数的特点,有目的的选择搜索的方向。
不过我的代码还是太繁琐了,其实不需要一直去判断 null,使用 0 来替代 null 即可。
代码
我自己的代码
1 | public class LC938 { |
其实可以写成这个样子
1 | public int rangeSumBST(TreeNode root, int low, int high) { |
2021/4/26
题目
难度中等264收藏分享切换为英文接收动态反馈
传送带上的包裹必须在 D 天内从一个港口运送到另一个港口。
传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 D 天内将传送带上的所有包裹送达的船的最低运载能力。
示例 1:
1 | 输入:weights = [1,2,3,4,5,6,7,8,9,10], D = 5 |
示例 2:
1 | 输入:weights = [3,2,2,4,1,4], D = 3 |
示例 3:
1 | 输入:weights = [1,2,3,1,1], D = 4 |
提示:
1 <= D <= weights.length <= 500001 <= weights[i] <= 500
思路
使用二分查找 + 贪心,二分查找判断可能的值,然后使用贪心来验证。
二分查找的上界是所有货物的重量,下界是货物中的最大重量。
使用贪心来查找,能拿就拿,不能拿就开下一次。
代码
1 | class Solution { |
其他
这种二分我还真的少接触
2021/4/25
题目
难度简单154收藏分享切换为英文接收动态反馈
给你一棵二叉搜索树,请你 按中序遍历 将其重新排列为一棵递增顺序搜索树,使树中最左边的节点成为树的根节点,并且每个节点没有左子节点,只有一个右子节点。
示例 1:
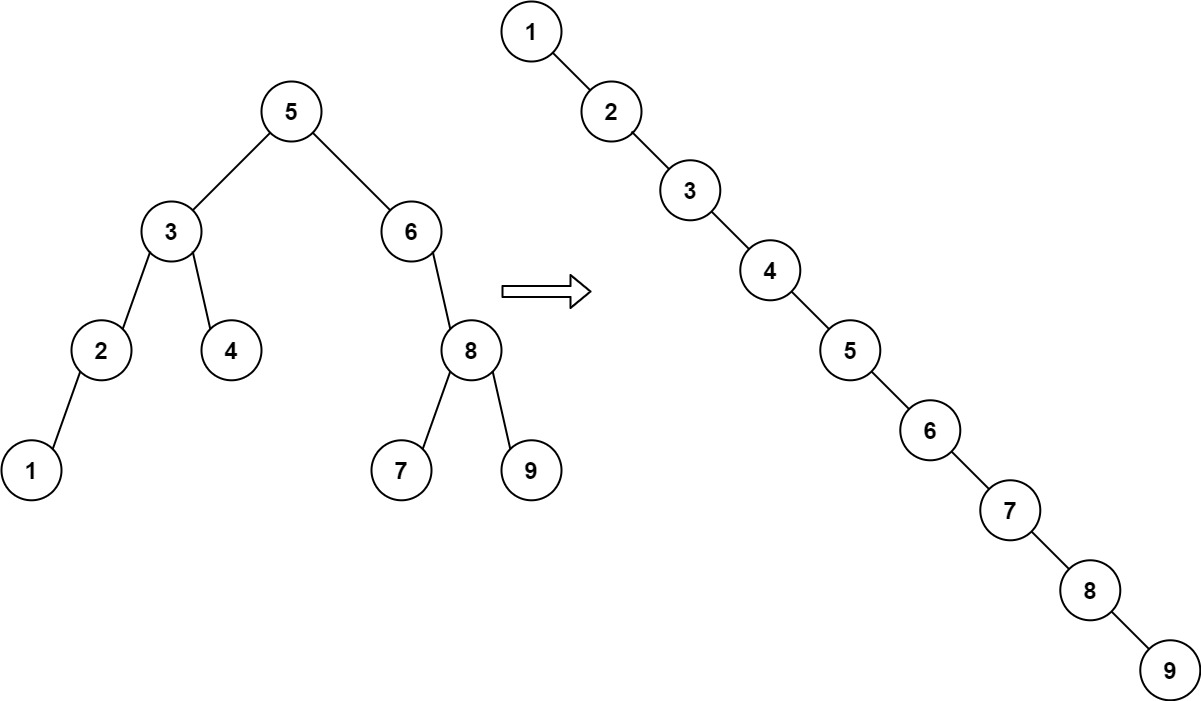
1 | 输入:root = [5,3,6,2,4,null,8,1,null,null,null,7,9] |
示例 2:
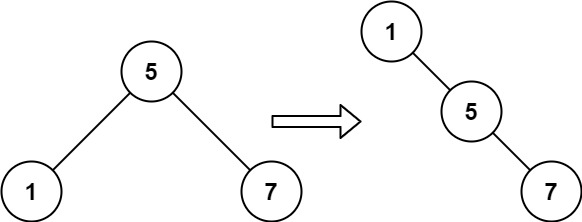
1 | 输入:root = [5,1,7] |
提示:
- 树中节点数的取值范围是
[1, 100] 0 <= Node.val <= 1000
思路
第一种,使用队列存储每个节点,然后修改原来的次序。
第二种,在中序遍历的时候,保存上一次节点,然后更改次序。
代码
1 | class Solution { |
其他
不得不说,人一钻牛角尖,就很难出来,这道题我想的太复杂了,什么左边搜索返回左边的最后一个节点,右边搜索返回右边的第一个节点,但是这是有问题的,搞来搞去,结果,根本不需要那么复杂,而且想的方向也是错的,得想个办法来打断自己的牛角尖状态。
2021/4/24
题目
难度中等408收藏分享切换为英文接收动态反馈
给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。
题目数据保证答案符合 32 位整数范围。
示例 1:
1 | 输入:nums = [1,2,3], target = 4 |
示例 2:
1 | 输入:nums = [9], target = 3 |
提示:
1 <= nums.length <= 2001 <= nums[i] <= 1000nums中的所有元素 互不相同1 <= target <= 1000
进阶:如果给定的数组中含有负数会发生什么?问题会产生何种变化?如果允许负数出现,需要向题目中添加哪些限制条件?
思路
深搜是不行的,因为顺序不同也是不同的组合,一旦数组里面有较小的数组,目标数字一大,甚至不需要那么大,那么必定超时。
正确的做法是使用DP,dp[i]表示目标是 i 的组合次数,dp 过程如下,遍历 1 ~ target,然后嵌套遍历数组,递推规则是dp[i] += dp[i-a],意思就是dp[i-a] + a可以达到 i 这个数值,由于每个数字都会被遍历,所以也满足不同顺序是不同组合的条件。
代码
1 | public int combinationSum4(int[] nums, int target) { |
2021/4/23
题目
难度中等333收藏分享切换为英文接收动态反馈
给你一个由 无重复 正整数组成的集合 nums ,请你找出并返回其中最大的整除子集 answer ,子集中每一元素对 (answer[i], answer[j]) 都应当满足:
answer[i] % answer[j] == 0,或answer[j] % answer[i] == 0
如果存在多个有效解子集,返回其中任何一个均可。
示例 1:
1 | 输入:nums = [1,2,3] |
示例 2:
1 | 输入:nums = [1,2,4,8] |
提示:
1 <= nums.length <= 10001 <= nums[i] <= 2 * 109nums中的所有整数 互不相同
思路
先使用 DP 递推出每个数字子集的个数,然后递推出子集的元素,假如一个数的子集元素数是4,那么它肯定是一个子集元素数是3的加上自身得到的,并且自身可以整除这个子集元素数是3的数。
根据这条性质,我们可以将最后得到的结果,从后面往前面递推,一步一步得到子集的所有元素。
切记,数组需要是有序的。
2021/4/19
题目
难度简单882收藏分享切换为英文接收动态反馈
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
1 | // nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 |
示例 1:
1 | 输入:nums = [3,2,2,3], val = 3 |
示例 2:
1 | 输入:nums = [0,1,2,2,3,0,4,2], val = 2 |
提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
思路
还是使用双指针,一个指向当前还没填放的位置,一个指向当前需要判断的位置。
代码
1 | public int removeElement(int[] nums, int val) { |
2021/4/18
题目
难度简单2021收藏分享切换为英文接收动态反馈
给你一个有序数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
1 | // nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 |
示例 1:
1 | 输入:nums = [1,1,2] |
示例 2:
1 | 输入:nums = [0,0,1,1,1,2,2,3,3,4] |
提示:
0 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按升序排列
思路
使用双指针,一个指向当前还没填放的位置,一个指向当前需要判断的位置。
代码
1 | public int removeDuplicates(int[] nums) { |
2021/4/17
题目
难度中等328收藏分享切换为英文接收动态反馈
给你一个整数数组 nums 和两个整数 k 和 t 。请你判断是否存在两个下标 i 和 j,使得 abs(nums[i] - nums[j]) <= t ,同时又满足 abs(i - j) <= k 。
如果存在则返回 true,不存在返回 false。
示例 1:
1 | 输入:nums = [1,2,3,1], k = 3, t = 0 |
示例 2:
1 | 输入:nums = [1,0,1,1], k = 1, t = 2 |
示例 3:
1 | 输入:nums = [1,5,9,1,5,9], k = 2, t = 3 |
提示:
0 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 10 <= k <= 1040 <= t <= 231 - 1
思路
解法一:
桶排思想 + 滑动窗口,根据 t 将取值范围划分为一个一个的桶(区间),例如,t 为 2,以为着运行两个数相差 2 ,也就是 0,2 是允许的,这时候会发现桶的最大长度是3,那么我们可以按 t + 1来划分桶。
在同一个桶内的两个元素一定是满足条件的,而相邻桶也可能出现满足条件的,按我们的划分,0-2是一个桶,3-5是一个桶,虽然 2,3 不是在同一个桶里面,但是它也满足条件,所以我们还需要判断相邻桶是否存在满足条件的。
超出窗口的记得移出桶。
解法二:
TreeSet + 滑动窗口,TreeSet可以快速的找到某个区间内的数据(可能不存在),那么我们拿到一个数据 data 以后,可以去寻找是否存在大于等于 data - t 的数据(这是下区间),并且该数据要小于等于 data + t(这是上区间),也就是找到[data - t,data + t]的元素。
注意,由于有加减操作,可能会溢出,记得用 Long
代码
方法一:
1 | // 桶排 |
方法二:1 | // 使用树 |
其他
不得不说,今天这道题学了不少,由于很少使用 TreeSet,所以都没有往这个东西上面想,桶排也是,果然,多接触接触,遇到问题,你才会往这上面想。
2021/4/16
题目
难度困难231收藏分享切换为英文接收动态反馈
使用下面描述的算法可以扰乱字符串 s 得到字符串 t :
- 如果字符串的长度为 1 ,算法停止
- 如果字符串的长度 > 1 ,执行下述步骤:
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
s,则可以将其分成两个子字符串x和y,且满足s = x + y。 - 随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,
s可能是s = x + y或者s = y + x。 - 在
x和y这两个子字符串上继续从步骤 1 开始递归执行此算法。
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
给你两个 长度相等 的字符串 s1 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回 true ;否则,返回 false 。
示例 1:
1 | 输入:s1 = "great", s2 = "rgeat" |
示例 2:
1 | 输入:s1 = "abcde", s2 = "caebd" |
示例 3:
1 | 输入:s1 = "a", s2 = "a" |
提示:
s1.length == s2.length1 <= s1.length <= 30s1和s2由小写英文字母组成
思路
分治,具体看题解吧,我大概懂了,刚才想的时候就感觉是用分治,但是没想到一个好的复杂度,原来是这题的复杂度本来就很高,唉。
代码
1 | class Solution { |
2021/4/15
题目
难度中等630收藏分享切换为英文接收动态反馈
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,能够偷窃到的最高金额。
示例 1:
1 | 输入:nums = [2,3,2] |
示例 2:
1 | 输入:nums = [1,2,3,1] |
示例 3:
1 | 输入:nums = [0] |
提示:
1 <= nums.length <= 1000 <= nums[i] <= 1000
思路
分区间DP,因为这是一个环,首尾是相连,那么将首尾分开dp,也就是计算(1,len-1)以及(2-len)这两个区间,看看放掉谁拿的更多。
我自己写的时候声明了一个比较长的数组,其实没必要,因为每一次只用到之前两个数。
看了一下题解,发现,题解不是保存上一个房间的两个状态,而是保存之前两间房间能偷的最大金额。
代码
自己:
1 | class Solution { |
题解:
1 | class Solution { |
2021/4/14
题目
难度中等621收藏分享切换为英文接收动态反馈
Trie**(发音类似 “try”)或者说 **前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
1 | 输入 |
提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
思路
题目说的很清楚,就是写前缀树,其实就是m叉树,在这题里面m对应了26个字母。然后根据插入的字符串一层一层排下去就可以了,记得创建一个变量表示当前位置是否是一个字符串的结尾。
题目有两个要求,第一个是求出是否包含某个字符串,第二个是求出前缀是否有某个字符串。其实就是根据我们设置的结束变量来判断。两者的代码是相同的,把共同的抽出来减少重复代码。
代码
1 | public class Trie { |
2021/4/13
题目
难度简单140收藏分享切换为英文接收动态反馈
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
注意:本题与 530:https://leetcode-cn.com/problems/minimum-absolute-difference-in-bst/ 相同
示例 1:
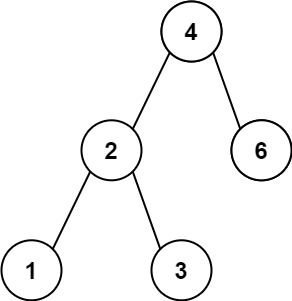
1 | 输入:root = [4,2,6,1,3] |
示例 2:
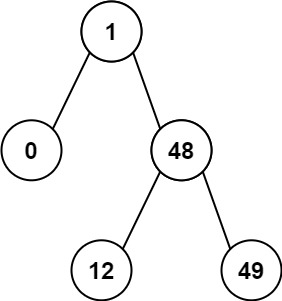
1 | 输入:root = [1,0,48,null,null,12,49] |
提示:
- 树中节点数目在范围
[2, 100]内 0 <= Node.val <= 105
思路
保存上一个节点的值,然后一个一个搜,然后两者相减并比较最小值,上一个节点的值可以初始化为 -10001,因为i的取值在[0,100000]之间,两者相减的最大值不可能大于10001。
代码
1 | public class LC783 { |
2021/4/12
题目
难度中等520收藏分享切换为英文接收动态反馈
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
示例 1:
1 | 输入:nums = [10,2] |
示例 2:
1 | 输入:nums = [3,30,34,5,9] |
示例 3:
1 | 输入:nums = [1] |
示例 4:
1 | 输入:nums = [10] |
提示:
1 <= nums.length <= 1000 <= nums[i] <= 109
思路
其实就是自定义排序,然后拼接字符串。Arrays.sort()是无法对基本数据类型进行自定义排序的,所以我就自己写了一个排序和比较规则。
这个比较规则其实就是 AB >= BA,也就是两个数字拼接起来,看看谁在前面更大,一开始我这个比较规则是用 String 来实现的,知道性能会很差了,确实很差,后面换成了数字。
记得去掉前导零!
代码
1 | public String largestNumber(int[] nums) { |
2021/4/11
题目
难度中等631收藏分享切换为英文接收动态反馈
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
1 | 输入:n = 10 |
示例 2:
1 | 输入:n = 1 |
提示:
1 <= n <= 1690
思路
暴力 = 最小堆 + HashSet,一个保证每一次拿出来的都是最小的丑数,一个保证丑数不重复,但是这种不用想,复杂度肯定很高。(小心溢出)
DP,dp[i]表示第 i 个丑数,每一次赋值,在 2,3,5 的倍数中选择一个最小的,也就是保存每个数字的当前倍数,1 * 2 没被拿走,肯定不可能拿 2 * 2。
代码
暴力
1 | public int nthUglyNumber(int n) { |
DP
1 | public int nthUglyNumber(int n) { |
2021/4/10
题目
难度简单229收藏分享切换为英文接收动态反馈
给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。
丑数 就是只包含质因数 2、3 和/或 5 的正整数。
示例 1:
1 | 输入:n = 6 |
示例 2:
1 | 输入:n = 8 |
示例 3:
1 | 输入:n = 14 |
示例 4:
1 | 输入:n = 1 |
提示:
-231 <= n <= 231 - 1
思路
贪心,只要能被2,3,5整除就除,最后判断一下是否是1就行了。也不需要考虑先除哪个数,先除2先除3没区别,小心 0 就行了。
代码
1 | public boolean isUgly(int n) { |
2021/4/9
题目
难度困难339收藏分享切换为英文接收动态反馈
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,4,4,5,6,7] 在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,4] - 若旋转
7次,则可以得到[0,1,4,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个可能存在 重复 元素值的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
示例 1:
1 | 输入:nums = [1,3,5] |
示例 2:
1 | 输入:nums = [2,2,2,0,1] |
提示:
n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums原来是一个升序排序的数组,并进行了1至n次旋转
进阶:
- 这道题是 寻找旋转排序数组中的最小值 的延伸题目。
- 允许重复会影响算法的时间复杂度吗?会如何影响,为什么?
思路
这道题和昨天的思路很相似,但是由于这边可能出现重复数据,所以可能会出现中间点和右边点相等的情况,这种情况下,你无法确定抛弃左边还是右边,但是你可以让右节点向左走一格,假如右节点是最小点也还有中点,假如不是,那么推进也没有问题。
代码
1 | public int findMin(int[] nums) { |
2021/4/8
题目
难度中等441收藏分享切换为英文接收动态反馈
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
- 若旋转
4次,则可以得到[4,5,6,7,0,1,2] - 若旋转
7次,则可以得到[0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
示例 1:
1 | 输入:nums = [3,4,5,1,2] |
示例 2:
1 | 输入:nums = [4,5,6,7,0,1,2] |
示例 3:
1 | 输入:nums = [11,13,15,17] |
提示:
n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums中的所有整数 互不相同nums原来是一个升序排序的数组,并进行了1至n次旋转
思路
使用二分查找,搜索出现断层的地方。如果右点比中点高,代表断层在左边(可能是中点),右指针移到中点,否则将左指针移到中点加1位置,加1是因为这时候不可能是中点,这时候中点比右点高,怎么可能是最小点。
代码
1 | public int findMin(int[] nums) { |
2021/4/7
题目
难度中等413收藏分享切换为英文接收动态反馈
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为 [4,5,6,6,7,0,1,2,4,4] 。
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果 nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
示例 1:
1 | 输入:nums = [2,5,6,0,0,1,2], target = 0 |
示例 2:
1 | 输入:nums = [2,5,6,0,0,1,2], target = 3 |
提示:
1 <= nums.length <= 5000-104 <= nums[i] <= 104- 题目数据保证
nums在预先未知的某个下标上进行了旋转 -104 <= target <= 104
进阶:
- 这是 搜索旋转排序数组 的延伸题目,本题中的
nums可能包含重复元素。 - 这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
思路
重复数据我觉得就没有必要二分了,直接遍历就行了。
代码
1 | public boolean search(int[] nums, int target) { |
2021/4/6
题目
难度中等494收藏分享切换为英文接收动态反馈
给你一个有序数组 nums ,请你** 原地** 删除重复出现的元素,使每个元素 最多出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
1 | // nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 |
示例 1:
1 | 输入:nums = [1,1,1,2,2,3] |
示例 2:
1 | 输入:nums = [0,0,1,1,1,1,2,3,3] |
提示:
1 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按升序排列
思路
方法一,每一次遇到重复的数把后面的数都往前移动一位,但是这种复杂度较高。
方法二,维护两个指针,一个指向当前遍历的位置,一个指向新数组填充的位置,如果不发生重复就将当前位置的值移到填充位置。
代码
方法一:
1 | public int removeDuplicates(int[] nums) { |
方法二:
1 | public int removeDuplicates(int[] nums) { |
2021/4/5
题目
难度简单830收藏分享切换为英文接收动态反馈
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。你可以假设 nums1 的空间大小等于 m + n,这样它就有足够的空间保存来自 nums2 的元素。
示例 1:
1 | 输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 |
示例 2:
1 | 输入:nums1 = [1], m = 1, nums2 = [], n = 0 |
提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-109 <= nums1[i], nums2[i] <= 109
思路
第一种,复制 nums1 的数据,然后遍历两个数组,比较小的数据放进 nums1 中,直到某一个数组为空,再把不为空的全部放进去。
第二种,第一种需要额外 m 的空间,但是换成从后面放的话,就不需要这额外的空间,从后往前,放比较大的。
代码
第一种
1 | public void merge(int[] nums1, int m, int[] nums2, int n) { |
第二种
1 | public void merge(int[] nums1, int m, int[] nums2, int n) { |
2021/4/4
题目
难度中等58收藏分享切换为英文接收动态反馈
森林中,每个兔子都有颜色。其中一些兔子(可能是全部)告诉你还有多少其他的兔子和自己有相同的颜色。我们将这些回答放在 answers 数组里。
返回森林中兔子的最少数量。
1 | 示例: |
说明:
answers的长度最大为1000。answers[i]是在[0, 999]范围内的整数。
思路
假如,有一只兔子说1,那么这个时候最少应该有2只兔子,自己和他嘴上的那只,那有两只兔子说1,那么还是两只,因为他们可以互指对方,如果有3只的话,那么就最少有4只了,因为两只互指,他们的颜色是一样的,多出来的一只颜色肯定是不相同的,而它说了1,代表着还有一只。
根据这个思路我们会发现,一个数字 n 所能容忍的相同颜色的兔子数是 n + 1,多出来的 1 是它们自身,那么当超过 n + 1之后,就需要重新计算颜色,也就是说如果小于等于 n + 1,那么就算 n + 1只,每多出一个 n + 1,就多 n + 1。也就是我们可以用下面的等式来计算 i 这个数字的兔子数
兔子数量 = (num[i] + i) / (i + 1) * (i + 1)
解释一下,num[i] + i是为了让未满 i + 1的数凑满 i + 1,例如 i 为 4,计算它能允许 5 个 4 ,但是不意味着所有兔子的说了,所以计算只有1个4,也得算 5 只兔子,除相同的数再乘相同的数,看起来没有意义?但是这是 Java,6 / 5 * 5,结果是什么就不用我说了吧 。
代码
1 | public int numRabbits(int[] answers) { |
2021/4/3
题目
难度中等420收藏分享切换为英文接收动态反馈
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
1 | 输入:text1 = "abcde", text2 = "ace" |
示例 2:
1 | 输入:text1 = "abc", text2 = "abc" |
示例 3:
1 | 输入:text1 = "abc", text2 = "def" |
提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
思路
经典 DP 问题,使用二维数组递推就行了,这种题,理解的了很简单,还没理解的,解释起来很麻烦,这里就不解释那么多,代码有一些注释。
代码
1 | public int longestCommonSubsequence(String text1, String text2) { |
2021/4/2
题目
难度中等135收藏分享切换为英文接收动态反馈
通常,正整数 n 的阶乘是所有小于或等于 n 的正整数的乘积。例如,factorial(10) = 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1。
相反,我们设计了一个笨阶乘 clumsy:在整数的递减序列中,我们以一个固定顺序的操作符序列来依次替换原有的乘法操作符:乘法(*),除法(/),加法(+)和减法(-)。
例如,clumsy(10) = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1。然而,这些运算仍然使用通常的算术运算顺序:我们在任何加、减步骤之前执行所有的乘法和除法步骤,并且按从左到右处理乘法和除法步骤。
另外,我们使用的除法是地板除法(floor division),所以 10 * 9 / 8 等于 11。这保证结果是一个整数。
实现上面定义的笨函数:给定一个整数 N,它返回 N 的笨阶乘。
示例 1:
1 | 输入:4 |
示例 2:
1 | 输入:10 |
提示:
1 <= N <= 10000-2^31 <= answer <= 2^31 - 1(答案保证符合 32 位整数。)
思路
因为 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 可以看做,x1 + 7 - x2 + 3 ,那我们将每一个 x 计算出来,然后用第一个 x 减去剩下所有就可以了,式子中间遇到 + 号的,直接加到答案上面。看代码很好理解,这个算法比题解的栈复杂度要好,因为一次计算几个数。
还有一个方法,就是使用栈,遇到 * / 号先计算,遇到 + 号则直接压进去,遇到 - 号则压入负数,最后相加栈里所有的元素即可。
最后还有一个方法,数学推导,其实我也想到了,这样的数会不会有规律,但是看到 1-4 和 5 - 8不一样,就放弃了,没想到居然是前4个没规律,后面的有,失算。
代码
方法一:
1 | public class LC1006 { |
方法二:
1 | public int clumsy(int N) { |
方法三:
1 | public int clumsy(int N) { |
2021/4/3
题目
难度困难217收藏分享切换为英文接收动态反馈
给定一个直方图(也称柱状图),假设有人从上面源源不断地倒水,最后直方图能存多少水量?直方图的宽度为 1。

上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的直方图,在这种情况下,可以接 6 个单位的水(蓝色部分表示水)。 感谢 Marcos 贡献此图。
示例:
1 | 输入: [0,1,0,2,1,0,1,3,2,1,2,1] |
思路
双指针,从左右往中间靠,选择两边高度最小的一方开始推进,这样做是为了防止溢出,推进的时候,如果遇到比自身大的则更新左节点,否则计算高度差。反复这个过程,直到两者相遇。
注意,记得加个特判。
代码
1 | public int trap(int[] height) { |
2021/3/31
题目
难度中等431收藏分享切换为英文接收动态反馈
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
示例 1:
1 | 输入:nums = [1,2,2] |
示例 2:
1 | 输入:nums = [0] |
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10
思路
先将数组进行排序,将相同数字放在一起,然后深搜,每一次深搜标记某个数字是否在这一次搜索里面被搜过,如果被搜过,那么跳过它,避免出现重复。
代码
1 | public class LC90 { |
2021/3/30
题目
难度中等382收藏分享切换为英文接收动态反馈
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:

1 | 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3 |
示例 2:
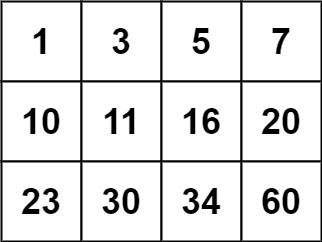
1 | 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13 |
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
思路
二分查找,不过需要处理一下而已,将二维数组看做一维,在那数值的时候换算一下行列即可。
题解还有一种二分,就是先在第一列找出不大于目标的数(最接近目标且不大于目标的数),然后在此列中再使用二分查找。
代码
个人方法:
1 | public boolean searchMatrix(int[][] matrix, int target) { |
题解:
1 | class Solution { |
2021/3/29
题目
难度简单304收藏分享切换为英文接收动态反馈
颠倒给定的 32 位无符号整数的二进制位。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数-1073741825。
进阶:
如果多次调用这个函数,你将如何优化你的算法?
示例 1:
1 | 输入: 00000010100101000001111010011100 |
示例 2:
1 | 输入:11111111111111111111111111111101 |
示例 1:
1 | 输入:n = 00000010100101000001111010011100 |
示例 2:
1 | 输入:n = 11111111111111111111111111111101 |
提示:
- 输入是一个长度为
32的二进制字符串
思路
比较基础的解法就是,改变权值,从 n 尾部一位一位取值,然后根据权值加上即可,时间固定是32次以内。
图解有一个很牛逼的解法,就是分支,要解决 32 位的颠倒,则先将 16 的颠倒,然后再把两个16位的颠倒,然后就16 -> 8 -> 4 -> 2 ,两位的交换挺简单了。下面举个例子:
00011101 -> 0 0 0 1 1 1 0 1 -> 00 10 11 10 -> 1000 1011 -> 10111000
为了实现这种互换,题解给出了一个思路,交换奇偶,当然这里的奇偶不是固定的,例如 1 0 0 1 这个时候每个单独的数字就是一位,但第二次的时候 10 01 ,两个才算一位,看代码理解一下。
代码
简单解法:
1 | public int reverseBits(int n) { |
题解解法:
1 | public class Solution { |
2021/3/28
题目
难度中等354收藏分享切换为英文接收动态反馈
实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
BSTIterator(TreeNode root)初始化BSTIterator类的一个对象。BST 的根节点root会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。boolean hasNext()如果向指针右侧遍历存在数字,则返回true;否则返回false。int next()将指针向右移动,然后返回指针处的数字。
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
示例:
1 | 输入 |
提示:
- 树中节点的数目在范围
[1, 105]内 0 <= Node.val <= 106- 最多调用
105次hasNext和next操作
进阶:
- 你可以设计一个满足下述条件的解决方案吗?
next()和hasNext()操作均摊时间复杂度为O(1),并使用O(h)内存。其中h是树的高度。
思路
和之前的迭代器一样,不使用那种直接搜索完存储在数组里面再一个一个返回的方法,这种其实比较简单。
我的解法是,使用一个栈来存储数据,当调用 next 的时候,弹出栈顶的元素,然后判断是不是没有左节点,如果有左节点,则把右节点压入和当前节点的值压入,然后再压入左节点,接着再调用一次自身。
当再调用自身的时候,就会再弹出左节点,重复上面的步骤,直到当前节点没有左节点,则再判断是否有右节点,然后再返回自身。
理解栈的话,我这个做法其实没有那么难。
代码
1 | import java.util.Stack; |
2021/3/27
题目
难度中等474收藏分享切换为英文接收动态反馈
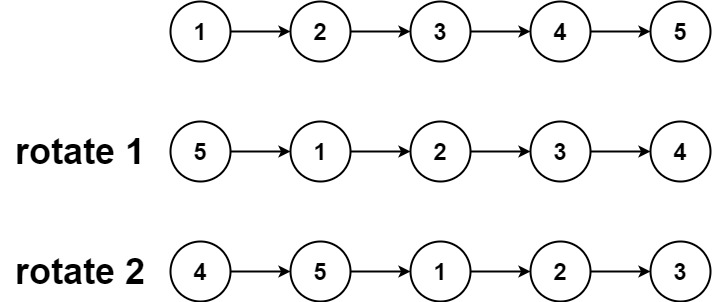
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
1 | 输入:head = [1,2,3,4,5], k = 2 |
示例 2:
1 | 输入:head = [0,1,2], k = 4 |
提示:
- 链表中节点的数目在范围
[0, 500]内 -100 <= Node.val <= 1000 <= k <= 2 * 109
思路
需要注意一下,这里 k 的取值是可能大于链表长度的,如果不大于的话,可以少去一步计算长度,大于的话,需要先把链表长度计算出来,然后将 k 的大小缩减到长度之内。
以实例1为例子,链表长度为5,k 为 2,以为着倒数第 k 个节点,也就是第二个节点会变成头结点,那么我们遍历到这个节点的前一个 pre 即可,然后将 pre 的 next 指向 null,然后将原来的尾结点指向头指针,这里的尾节点可以在找到 pre 的时候继续往后走找到,也可以在一开始计算长度的时候保存。
代码
1 | public ListNode rotateRight(ListNode head, int k) { |
2021/3/26
题目
难度简单543收藏分享切换为英文接收动态反馈
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
示例 1:
1 | 输入:head = [1,1,2] |
示例 2:
1 | 输入:head = [1,1,2,3,3] |
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
思路
这道题比起昨天的就比较简单了,可以站在当前节点看下一个节点,如果相同则跳过该节点,直到不同或者没有下一个节点,则走向下一个。
代码
1 | public ListNode deleteDuplicates(ListNode head) { |
2021/3/25
题目
难度中等543收藏分享切换为英文接收动态反馈
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:

1 | 输入:head = [1,2,3,3,4,4,5] |
示例 2:

1 | 输入:head = [1,1,1,2,3] |
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
思路
如果链表为空就直接返回,否则先给 head 再创建一个前结点 pre。
需要保证 head 以及 head.next 都不为空
- head 走一步,通过 pre 判断 pre.next 和 head 的值是否相等
- 如果相等,head 一直往后走,直到值不等或者自身为空
- 然后 pre 指向此时的 head,等于跳过了所有重复的
- 如果不等,pre = pre.next
- 如果相等,head 一直往后走,直到值不等或者自身为空
代码
1 | public ListNode deleteDuplicates(ListNode head) { |
2021/3/24
题目
难度中等302收藏分享切换为英文接收动态反馈
给定一个整数序列:a1, a2, …, an,一个132模式的子序列 ai, aj, ak 被定义为:当 i < j < k 时,ai < ak < aj。设计一个算法,当给定有 n 个数字的序列时,验证这个序列中是否含有132模式的子序列。
注意:n 的值小于15000。
示例1:
1 | 输入: [1, 2, 3, 4] |
示例 2:
1 | 输入: [3, 1, 4, 2] |
示例 3:
1 | 输入: [-1, 3, 2, 0] |
思路
固定1,遍历3,找出2(1 2 3 是指大小关系)。
从头遍历到尾,以 3 为遍历点,1 可以通过保存左边最小的值求出,2 的话可以通过将右侧所有值保存在 TreeMap 里面,然后根据当前的 1 来求出最符合的 2,也就是 Map 里面比 1 大的最小数,接着判断 2 和 3 的大小关系,如果 3 大于 2,则返回 true。
上面这种解法运行完发现效率不是那么好,也是,因为涉及频繁的 Map 更新。然后就在别人的提交里面又找了一份时间消耗比较良好的。思路如下:
- 存储每个位置的最小值,例如 a[ i ]表示 0 - i 里面的最小值。
- 维护一个栈,用于保存可能的 2
- 然后从尾想前遍历
- 如果当前数比前面的最小值大,则将栈里面比最小值要小的数弹出栈,直到栈空或者栈顶元素大于最小值,然后比较栈顶元素和当前数的大小,满足条件返回 True,否则将当前值压入栈
说起来好像有点玄乎,其实看代码还好理解。
代码
解法1:
1 | class Solution { |
解法2:
1 | class Solution { |
2021/3/23
题目
难度中等215收藏分享切换为英文接收动态反馈
给你一个嵌套的整型列表。请你设计一个迭代器,使其能够遍历这个整型列表中的所有整数。
列表中的每一项或者为一个整数,或者是另一个列表。其中列表的元素也可能是整数或是其他列表。
示例 1:
1 | 输入: [[1,1],2,[1,1]] |
示例 2:
1 | 输入: [1,[4,[6]]] |
思路
使用栈进行存储迭代器。
- 如果迭代器指向的下一个为整数,则创建一个 list ,将它存储回去,接着再把迭代器存入主数据里面
- 如果指向的是一个集合,则存回这个集合的迭代器
但是这种方法其实效率比较低,因为你遇到数字还需要创建一个迭代器只指向这个数字,这种行为效率很低。
有一个效率比较高的方法,就是使用深搜。深搜步骤如下:
- 使用一个集合存储所有数据
- 遍历当前迭代器
- 如果指向的是数字,则存入集合
- 如果是集合,则再调用自己
- 直到遍历完,这样就把里面所有的数据拿出来了
这种方法虽然效率高,但是不符合迭代器的思想,迭代器不应该自己去处理数据,它应该只是一个游标一样的东西。
深搜也不难,这里就不写了。
代码
1 | import java.util.ArrayList; |
2021/3/22
题目
难度简单275收藏分享切换为英文接收动态反馈
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
示例 1:
1 | 输入:00000000000000000000000000001011 |
示例 2:
1 | 输入:00000000000000000000000010000000 |
示例 3:
1 | 输入:11111111111111111111111111111101 |
提示:
- 输入必须是长度为
32的 二进制串 。
进阶:
- 如果多次调用这个函数,你将如何优化你的算法?
思路
使用位操作, n &= (n-1) 每一次会消去最后面的1,计算这个等式使用的次数即可判断出有多少个 1 。
当然,使用位操作也行,判断 n 的最后一位数,然后将 n 向右位移。
代码
1 | public int hammingWeight(int n) { |
2021/3/21
题目
难度中等413收藏分享切换为英文接收动态反馈
给定一个 *m* x *n* 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
进阶:
- 一个直观的解决方案是使用
O(*m**n*)的额外空间,但这并不是一个好的解决方案。 - 一个简单的改进方案是使用
O(*m* + *n*)的额外空间,但这仍然不是最好的解决方案。 - 你能想出一个仅使用常量空间的解决方案吗?
示例 1:
1 | 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]] |
示例 2:
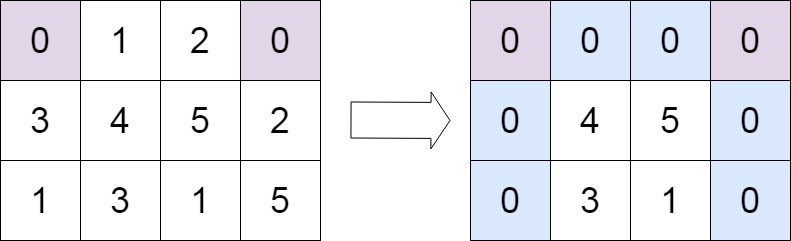
1 | 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]] |
提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-231 <= matrix[i][j] <= 231 - 1
思路
如果不要求空间复杂度为 O(n+m) ,那么还是挺简单的,找两个标识数组分别来保存行和列的情况,遍历完以后,根据两个标识数组来将某行某列归零。
空间复杂度为常数的话,则需要使用数组自身来记录也就是使用第一行第一列来充当上面的两个标识数组,不过需要额外使用两个变量来保存第一行和第一列的情况,然后遍历下面的。
代码
1 | class Solution { |
题目
难度中等1455收藏分享切换为英文接收动态反馈
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
1 | 输入:nums = [10,9,2,5,3,7,101,18] |
示例 2:
1 | 输入:nums = [0,1,0,3,2,3] |
示例 3:
1 | 输入:nums = [7,7,7,7,7,7,7] |
提示:
1 <= nums.length <= 2500-104 <= nums[i] <= 104
进阶:
- 你可以设计时间复杂度为
O(n2)的解决方案吗? - 你能将算法的时间复杂度降低到
O(n log(n))吗?
思路
使用 DP 解法,dp[i]表示以 num[i] 结尾的上升子序列的长度。然后遍历每一个数,找到它前面能合并的最长子序列。
代码
1 | public int lengthOfLIS(int[] nums) { |
其他
今天第二道题是被别人问,不过他的题比较复杂,需要求出响应的子序列,然后长度相同还要找出字符集最小的。没在力扣找到相同的题,只找到了这道,不过根据上面的解法,他那道也是可以解的,就是复杂了一点,思路如下:
首先,再加一个数组来保存每个位置上一个字符的下标(保存的时候,保存字符集最小的),根据上面求出的最长子序列大小,找出所有该长度的,然后求出对应的子序列,计算大小,保存最小的。说起来简单,实际写起来应该还是有点小麻烦。
2021/3/20
题目
难度中等289收藏分享切换为英文接收动态反馈
根据 逆波兰表示法,求表达式的值。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
- 整数除法只保留整数部分。
- 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
1 | 输入:tokens = ["2","1","+","3","*"] |
示例 2:
1 | 输入:tokens = ["4","13","5","/","+"] |
示例 3:
1 | 输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] |
提示:
1 <= tokens.length <= 104tokens[i]要么是一个算符("+"、"-"、"*"或"/"),要么是一个在范围[-200, 200]内的整数
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 )。 - 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * )。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + *也可以依据次序计算出正确结果。 - 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
思路
逆波兰式也就是后缀表达式,正常的话,应该是让你前缀转后缀再计算那还好说,单纯的后缀计算挺简单的。
遇到数字压入栈,遇到符号弹出两个来运算,需要注意的是 - 和 / 的,先弹出来的是在后面的。
还有就是,这里面的数字是可以带符号的,也就是不能单纯通过第一个字符来判断,顺便判断一下长度
代码
1 | public int evalRPN(String[] tokens) { |
2021/3/19
题目
请你给一个停车场设计一个停车系统。停车场总共有三种不同大小的车位:大,中和小,每种尺寸分别有固定数目的车位。
请你实现 ParkingSystem 类:
ParkingSystem(int big, int medium, int small)初始化ParkingSystem类,三个参数分别对应每种停车位的数目。bool addCar(int carType)检查是否有carType对应的停车位。carType有三种类型:大,中,小,分别用数字1,2和3表示。一辆车只能停在carType对应尺寸的停车位中。如果没有空车位,请返回false,否则将该车停入车位并返回true。
示例 1:
1 | 输入: |
提示:
0 <= big, medium, small <= 1000carType取值为1,2或3- 最多会调用
addCar函数1000次
思路
这还有什么好说的,就一个点,不存在位置的增加(车只负责进,不负责走),不要 if 判断,每一次都递减判断
代码
1 | public class LC1603 { |
2021/3/18
题目
难度中等723收藏分享切换为英文接收动态反馈
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
说明:
1 ≤ m ≤ n ≤ 链表长度。
示例:
1 | 输入: 1->2->3->4->5->NULL, m = 2, n = 4 |
思路
首先创建一个虚拟头指针,因为可能反转整个链表。
保存 m 节点的前一个节点 pre ,保存当前链表的下一个节点 next ,保存头指针 ans,保存 m 节点 mNode。然后遍历需要反转的区间,对每一个节点 node 做以下操作
- 保存当前节点 node 的下一个节点 next
- 当前节点的 node 下一个节点指向 pre 下一个节点
- pre 的下一个节点指向当前节点 node
上面的操作每一次都将节点插到 pre 后面,但是第一个会出现自循环的时候(自己的下一个节点指向自己)。
但是我们上面保存了 m 节点(也就是循环的第一个节点),将循环空间后面链表接到 m 节点后面。
代码
1 | /** |
2021/3/17
题目
难度困难479收藏分享切换为英文接收动态反馈
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 1:
1 | 输入:s = "rabbbit", t = "rabbit" |
示例 2:
1 | 输入:s = "babgbag", t = "bag" |
思路
使用 DP 来递推出子串的重复次数,本人使用的是从后往前递归的方法。
dp[i][j]表明,字符串 S 从 i 到 末尾的子串 和 T 从 j 到末尾子串的重复次数,这里有一个注意点,这里的子串不等于 T!
当 i = S.length() 的时候,是空串,空串不包括任何子串(除了空串自身),这个时候,全部设置为0,当 j = T.length() 的时候,是空串,空串是任何字符串的子串,全部设置为1。
然后从后面的递推回来,如果当前 i ,j 指向的字符相同,那么这时候的字符串个数由两边合并得到,dp[i+1][j+1] + dp[i+1][j],由上一次自己的个数,以及上一次上一个字符的个数的总和,有点难理解,dubug 看一遍过程比较好理解。
第二个则是,指向的字符不同,那么只能从上一次自己得到dp[i+1][j]
代码
1 | public int numDistinct(String s, String t) { |
提示:
0 <= s.length, t.length <= 1000s和t由英文字母组成
2021/3/16
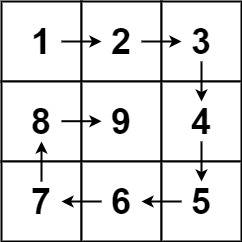
题目
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
1 | 输入:n = 3 |
示例 2:
1 | 输入:n = 1 |
提示:
1 <= n <= 20
思路
当使用变量维护四个边际之后,一切就变得简单多了。今天的题和昨天的基本一样,只不过从输出变成了构建。一样是绕圈,然后,使用一个变量自增即可。
代码
1 | public int[][] generateMatrix(int n) { |
2021/3/15
题目
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:

1 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] |
示例 2:

1 | 输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]] |
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
思路
维护四个变量,分别代表上下左右,然后绕圈拿数即可
我以前都是靠自己脑子想,明明找个变量维护就好了,傻!
代码
1 | public List<Integer> spiralOrder(int[][] matrix) { |
2021/3/14
题目
难度简单136收藏分享切换为英文接收动态反馈
不使用任何内建的哈希表库设计一个哈希映射(HashMap)。
实现 MyHashMap 类:
MyHashMap()用空映射初始化对象void put(int key, int value)向 HashMap 插入一个键值对(key, value)。如果key已经存在于映射中,则更新其对应的值value。int get(int key)返回特定的key所映射的value;如果映射中不包含key的映射,返回-1。void remove(key)如果映射中存在key的映射,则移除key和它所对应的value。
示例:
1 | 输入: |
提示:
0 <= key, value <= 106- 最多调用
104次put、get和remove方法
进阶:你能否不使用内置的 HashMap 库解决此问题?
思路
和昨天的差不多,加点东西而已
代码
1 | /* |
2021/3/13
题目
不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
实现 MyHashSet 类:
void add(key)向哈希集合中插入值key。bool contains(key)返回哈希集合中是否存在这个值key。void remove(key)将给定值key从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
示例:
1 | 输入: |
提示:
0 <= key <= 106- 最多调用
104次add、remove和contains。
思路
由于只是简单实现,就数组加链表。
一开始写了一个,觉得贼复杂,特判很多,后面就给数组每一个链表设置一个头结点,然后代码就清楚多了。
这个实现就没什么好说的吧,挺基础的,具体看代码
代码
1 | class MyHashSet { |
2021/3/12
题目
序列化二叉树的一种方法是使用前序遍历。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
1 | _9_ |
例如,上面的二叉树可以被序列化为字符串 "9,3,4,#,#,1,#,#,2,#,6,#,#",其中 # 代表一个空节点。
给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。编写一个在不重构树的条件下的可行算法。
每个以逗号分隔的字符或为一个整数或为一个表示 null 指针的 '#' 。
你可以认为输入格式总是有效的,例如它永远不会包含两个连续的逗号,比如 "1,,3" 。
示例 1:
1 | 输入: "9,3,4,#,#,1,#,#,2,#,6,#,#" |
示例 2:
1 | 输入: "1,#" |
示例 3:
1 | 输入: "9,#,#,1" |
思路
由于本题使用的是前序遍历,所以可以使用占槽法,一个不为空的节点会消耗一个槽位,并带来两个新槽位,一个为空的槽位会消耗一个槽位。最后如果槽位刚好占满,则返回可以。
代码
1 | public boolean isValidSerialization(String preorder) { |
题目
数组中占比超过一半的元素称之为主要元素。给定一个整数数组,找到它的主要元素。若没有,返回-1。
示例 1:
1 | 输入:[1,2,5,9,5,9,5,5,5] |
示例 2:
1 | 输入:[3,2] |
示例 3:
1 | 输入:[2,2,1,1,1,2,2] |
说明:
你有办法在时间复杂度为 O(N),空间复杂度为 O(1) 内完成吗?
思路
这道题不是今天的每日一题,但是我觉得有必要加到这里面来说,因为这个解法太妙了(在笔试题里遇到)
我看到这题,第一反应是 Hash 存储,然后判断某个数字是否大于一半,但是还有更加简单的,就是摩尔投票算法。
思路很简单,如果这个数组存在一个数的数量大于数组的一般,那么将这个数和其他数一一抵消,那么最后剩下的一定是这个数。
具体实现,遍历数组,然后将不同的数字抵消,如果最后剩下一个数,那么再遍历一次数组,计算这个数字是否超过一半。再遍历一次的原因是,可能这个数没有大于一般,但是前面的数两两打架,抵消了,例如[1,2,3,4,5],抵消到最后,只剩下一个5,但是5不大于一半。
代码
1 | public int majorityElement(int[] nums) { |
2021/3/11
题目
难度中等342收藏分享切换为英文接收动态反馈
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
整数除法仅保留整数部分。
示例 1:
1 | 输入:s = "3+2*2" |
示例 2:
1 | 输入:s = " 3/2 " |
示例 3:
1 | 输入:s = " 3+5 / 2 " |
提示:
1 <= s.length <= 3 * 105s由整数和算符('+', '-', '*', '/')组成,中间由一些空格隔开s表示一个 有效表达式- 表达式中的所有整数都是非负整数,且在范围
[0, 231 - 1]内 - 题目数据保证答案是一个 32-bit 整数
思路
一眼我就又想到了中缀转后缀,不过今天倒是没有坑,过了,我一开始还怕给我两个乘完会溢出的数,结果居然没有,不然就得改一下类型了。
看完题解,我真傻,没必要算这么多,又没有括号,不得不说,题解太妙了。题解代码我也会贴上来,加上一些注释
代码
个人贼长的代码(下一次遇到这种,先想想题解这种了)
1 | public int calculate(String s) { |
题解
1 | class Solution { |
2021/3/10
题目
实现一个基本的计算器来计算一个简单的字符串表达式 s 的值。
示例 1:
1 | 输入:s = "1 + 1" |
示例 2:
1 | 输入:s = " 2-1 + 2 " |
示例 3:
1 | 输入:s = "(1+(4+5+2)-3)+(6+8)" |
提示:
1 <= s.length <= 3 * 105s由数字、'+'、'-'、'('、')'、和' '组成s表示一个有效的表达式
思路
第一眼就想到中缀转后缀计算,然后一通狂写,发现一个问题,如果表达式是 “1–1”,这种,因为 - 号即可以是一元运算符,也可以是二元运算符,表达式的中缀转后缀结果是 “1-1-“ 也就是 -1 - 1,答案是 - 2,但是正确答案是 2。硬要做也不是不行,就是在转后缀的时候,遇到两个符号相连,合并起来就可以了,但是那样我觉得太麻烦了。
看了题解,发现果然没有那么麻烦,题解的思路是:
由于只有 + - 两者符号,那么我确定当前的符号是正还是负就可以了,遇到括号的话,根据括号前的符号来改变括号内的运算符。例如,-(1+2),那么这个时候这个 + 应该是 - ,使用一个栈来保存,因为括号结束的时候,要返回上一个状态
代码
1 | public int calculate(String s) { |
2021/3/9
题目
难度简单208收藏分享切换为英文接收动态反馈
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
1 | 输入:"abbaca" |
提示:
1 <= S.length <= 20000S仅由小写英文字母组成。
思路
使用栈一个一个存储字符,如果准备加入的字符和栈顶的字符一样,则弹出栈顶的并且不把新字符加入栈,重复这一过程即可。
不一定需要使用栈(我想到栈就用栈了),也可以使用 StringBuilder 这种可变字符串,思路一样的,append 之前查看字符串的尾部即可。
代码
1 | public String removeDuplicates(String S) { |
2021/3/8
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
示例 1:
1 | 输入:s = "aab" |
示例 2:
1 | 输入:s = "a" |
示例 3:
1 | 输入:s = "ab" |
提示:
1 <= s.length <= 2000s仅由小写英文字母组成
思路
先预处理数据,得出每个子串是否是回文串,然后就可以直接递归求出 dp[0] [i]的值了
代码
1 | public int minCut(String s) { |
2021/3/7
题目
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
1 | 输入:s = "aab" |
示例 2:
1 | 输入:s = "a" |
提示:
1 <= s.length <= 16s仅由小写英文字母组成
思路
两种思路,一种是使用 DP 先预处理所有的字符串,然后使用回溯切割,另外一种就是直接使用回溯切割,然后在判断回文字符串的时候用记忆化数组进行优化。
第二种需要注意下,这里的时候记忆化数组进行优化不单单只是保存答案,而是在求当前字符串是否是回文的时候,顺便判断一下子串。我一开始只是保存答案,发现没什么多大优化。
代码
下面两种代码都是题解代码
第一种
1 | class Solution { |
第二种
1 | class Solution { |
2021/3/6
题目
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
示例 1:
1 | 输入: [1,2,1] |
注意: 输入数组的长度不会超过 10000。
思路
使用单调栈来求出答案,单调栈,顾名思义就是栈里的元素都是单调递增或者递减的。解法如下:
- 两次遍历数组(由于是循环数组,所以需要两次),将当前数据 now 和栈顶数据 top 进行比较
- 如果当前数据 now 小于等于栈顶数据 top 则将当前数据压入栈
- 如果当前数据 now 大于栈顶数据 top 则将所有小于当前数据 now 的栈顶数据全部弹出,并将这些数据的答案设置为当前数据 now
注意,此题栈内保存的是下标。
1 | public int[] nextGreaterElements(int[] nums) { |
2021/3/5
题目
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列的支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你只能使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
进阶:
- 你能否实现每个操作均摊时间复杂度为
O(1)的队列?换句话说,执行n个操作的总时间复杂度为O(n),即使其中一个操作可能花费较长时间。
示例:
1 | 输入: |
提示:
1 <= x <= 9- 最多调用
100次push、pop、peek和empty - 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop或者peek操作)
思路
因为只会往队尾添加元素,所以设置一个栈应用保存添加进来的元素,取的时候从另一个栈取,如果该栈为空,则就保存栈的数据移动过去。由于保存栈的栈顶是尾部,弹出来添加过去的时候,也刚好在取出栈的栈顶。
代码
1 | public class LC232 { |
2021/3/4
题目
给定一些标记了宽度和高度的信封,宽度和高度以整数对形式 (w, h) 出现。当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算最多能有多少个信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
说明:
不允许旋转信封。
示例:
1 | 输入: envelopes = [[5,4],[6,4],[6,7],[2,3]] |
思路
二维数据固定一维,对另外一维求解。
假设将宽度 width 按升序排序,在不出现重复的情况下,后面的永远可以套上前面的,这样问题就变成了,求高度的最长递增子序列了。
但是题目是会出现宽度相等的情况,所以需要处理一下,假设出现[[2,1],[2,2],[2,3],[2,4]] 这种情况,按照题意,应该是一个的,但是根据我们上面的解法,[1,2,3,4],答案是四个。处理方法就是将相等等宽度,高度递减排序,也就是变成了[4,3,2,1],这样就只能取一个了。
我再多想一步就想出这个方法了,可惜,原来相等的这么处理就行了
代码
1 | public int maxEnvelopes(int[][] envelopes) { |
2021/3/3
题目
难度中等543收藏分享切换为英文接收动态反馈
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
示例 1:
1 | 输入: 2 |
示例 2:
1 | 输入: 5 |
进阶:
- 给出时间复杂度为O(n*sizeof(integer))**的解答非常容易。但你可以在线性时间O(n)**内用一趟扫描做到吗?
- 要求算法的空间复杂度为**O(n)**。
- 你能进一步完善解法吗?要求在C++或任何其他语言中不使用任何内置函数(如 C++ 中的 __builtin_popcount)来执行此操作。
思路
采用动态规划的思想,首先将这个数 n 和 n-1 进行与操作,会出现两种情况
- 第一种就是0,出现这种情况,就是出现了进位,比如 011 -> 100 ,直接将这个 n 的值设置为1即可
- 第二种就是非0的值 x,这个 x 无论如何都比 n 小,并且 n - x 也比 n 小,根据 DP 的算法,比 n 小的都是已知的,可以直接通过 data[n -x] + data[x] 来求出当前的值
根据这个一直算下去就可以了
题解的解法看起来和我差不多,不过人家是维护一个最高位 y,然后如果出现 0 的情况就更新最高位 y 的值,通过 data[n - y] + 1来求出值。
代码
我自己的
1 | public int[] countBits(int num) { |
题解维护最高位代码(比我简洁多了)
1 | public int[] countBits(int num) { |
2021/3/2
题目
难度中等163收藏分享切换为英文接收动态反馈
给定一个二维矩阵,计算其子矩形范围内元素的总和,该子矩阵的左上角为 (row1, col1) ,右下角为 (row2, col2) 。

上图子矩阵左上角 (row1, col1) = (2, 1) ,右下角(row2, col2) = (4, 3),该子矩形内元素的总和为 8。
示例:
1 | 给定 matrix = [ |
提示:
- 你可以假设矩阵不可变。
- 会多次调用
sumRegion方法。 - 你可以假设
row1 ≤ row2且col1 ≤ col2。
思路
方法一,计算出每一列的前缀和,然后根据两个坐标点,分别算出每一行的,再把答案相加。
方法二,计算二维的前缀和,定义 sums[i] [j] 等于横纵坐标都小于该点的总值,例如,假如 sums [1] [1]就是下面黄色的这一块
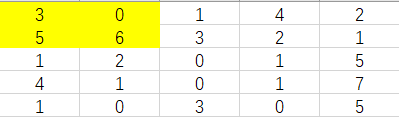
计算出这个以后,就可以直接求出答案了,假如求 sumRegion(2, 1, 4, 3)
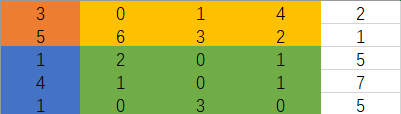
首先我们可以通过 sums[4] [3]拿出这四个颜色的总和,而我们只需要求绿色的这一块,sums[1] [3]拿出黄色和橙色这两块,sums[4] [0]拿出橙色和蓝色这两块,sum[1] [0]拿出橙色这一块,接着拿 sums[4] [3] - sums[1] [3] - sums[4] [0] + sum[1] [0],就可以求出绿色的了。
代码
一维前缀和
1 | public class LC304 { |
二维前缀和
1 | class NumMatrix { |
2020/12/4(补)
题目
给你一个按升序排序的整数数组 num(可能包含重复数字),请你将它们分割成一个或多个长度至少为 3 的子序列,其中每个子序列都由连续整数组成。
如果可以完成上述分割,则返回 true ;否则,返回 false 。
示例 1:
1 | 输入: [1,2,3,3,4,5] |
示例 2:
1 | 输入: [1,2,3,3,4,4,5,5] |
示例 3:
1 | 输入: [1,2,3,4,4,5] |
提示:
1 <= nums.length <= 10000
思路
采用哈希表 + 优先队列,遍历数组,访问当前的数据n的时候,查看是否有以n-1结尾的队列,如果有,则把该n加到最短的队列后面,否则创建一个以n开头的队列。最后遍历所有队列,如果长度都大于等于3,则返回真,否则返回假。
上面这个解法,好是好,但是太费时间了,在提交里面有看到另外一个解法,思路如下:
- 使用三个变量存储长度分别为1,2,大于等于3的队列的个数
- 遍历数据,每一次将相同的数据拿出来,然后判断该数据能否连上上一个数据。
- 如果不可以,判断当前队列长度是否全大于3,如果全大于3,则放弃前面所有队列,然后新建当前相同数据个数的长度为1的队列,否则抛弃返回 false
- 如果可以,判断是否能分配到所有队列长度为1和2后面
- 如果不够则返回 false
- 如果够,则更新三个数据,计算更新完队列1和2剩下的个数,然后和队列3取最小的,设为m。接着队列2更新为队列1,队列3 = 队列2 + m,更新队列1为剩下的数
- 最后判断队列1和2是否都为0,为0返回 true 否则返回false。
代码
哈希表 + 优先队列
1 | public boolean isPossible(int[] nums) { |
较优算法
1 | public boolean isPossible(int[] nums) { |
20202/12/9(补)
题目
难度中等843收藏分享切换为英文接收动态反馈
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
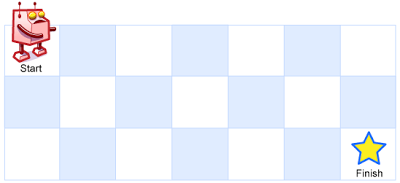
1 | 输入:m = 3, n = 7 |
示例 2:
1 | 输入:m = 3, n = 2 |
示例 3:
1 | 输入:m = 7, n = 3 |
示例 4:
1 | 输入:m = 3, n = 3 |
提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
思路
DP,初始化两边,然后更新到终点。
组合排列,高中知识
代码
DP
1 | class Solution { |
组合
1 | public int uniquePaths(int m, int n) { |
组合简单写法(题解写法)
1 | class Solution { |
2020/12/11
题目
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的**一**项:
禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
宣布胜利:
如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
示例 1:
1 | 输入:"RD" |
示例 2:
1 | 输入:"RDD" |
提示:
- 给定字符串的长度在
[1, 10,000]之间.
思路
贪心算法解决,每一个有票的人,只需要干掉离自己最近的对方阵营的人即可,当一个阵营没人,留下来的就是胜利的!
代码
1 | public String predictPartyVictory(String senate){ |
2020/12/12
题目
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
示例 1:
1 | 输入: [1,7,4,9,2,5] |
示例 2:
1 | 输入: [1,17,5,10,13,15,10,5,16,8] |
示例 3:
1 | 输入: [1,2,3,4,5,6,7,8,9] |
进阶:
你能否用 O(n) 时间复杂度完成此题?
思路
采用DP,从头到尾递推即可。
使用两个变量,hLen表示升序序列长度,lLen表示降序序列长度,都初始化为1
如果当前的数据比前一个数据大,则更新hLen,hLen = max(lLen + 1 , hLen),如果比前一个数据小,则更新lLen,lLen = max(hLen + 1, lLen)。
为什么可以用前一个数据代替摆动数列的尾部呢?因为如果这一次比较无法更新数据,则用当前数据顶替尾部数据,例如当前摆动数列的尾部为7(上升),升序长度为10,当前数据为9,更新降序长度后,因为升序的下一个只能找降序,所以用10顶替7没有问题。
代码
1 | public int wiggleMaxLength(int[] nums){ |
2020/12/13
题目
给定一个整数数组,判断是否存在重复元素。
如果任意一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例 1:
1 | 输入: [1,2,3,1] |
示例 2:
1 | 输入: [1,2,3,4] |
示例 3:
1 | 输入: [1,1,1,3,3,4,3,2,4,2] |
思路
暴力的就排序,然后遍历数组,比较前后两个数字是否相同。
优化一点就使用HashSet来存储数据,然后根据HashSet的size()和数组长度进行比较,如果一致,则无重复。这个还可以进一步剪枝,因为Set的add()方法根据添加成功与否会返回一个boolean值,如果出现一次添加失败,则可以判断有重复数据
代码
1 | public boolean containsDuplicate(int[] nums) { |
2020/12/14
题目
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
1 | 输入: ["eat", "tea", "tan", "ate", "nat", "bat"] |
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
思路
解法一(我的解法)给每一个字符串一个Hash值,Hash值的有如下规则
- 不同长度的字符串Hash值一定不等
- 相同长度,组成字母一样的字符串Hash值相等
具体实现看代码,不过这是很取巧的方式,因为一旦字符串的长度很长,位数的设置值太大,使得int超出范围(不过采取long类型可以避免),由于字符的值最大才25(字符 - ‘a’),所以才能平方那么多次,不过代价就是运行慢,主要时间都花费在计算Hash值(也可以采取其他计算方法,例如映射成质数,然后把映射的值相乘取mod,由于Hash的计算方法简单,而且没有其他处理,所以肯定存在某个数Hash相同而构成不同)
解法二:
将每一个字符串转化成char[],这样就可以对数组进行排序,排序完再转化成String,然后通过HashMap来存储,相同构成字符串在排序后是一样的,这种就比我的快多了
代码
解法一
1 | public List<List<String>> groupAnagrams(String[] strs) { |
解法二
1 | public List<List<String>> groupAnagrams(String[] strs) { |
2020/12/15
题目
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
示例 1:
1 | 输入: N = 10 |
示例 2:
1 | 输入: N = 1234 |
示例 3:
1 | 输入: N = 332 |
说明: N 是在 [0, 10^9] 范围内的一个整数。
思路
解法一:
转换成从头到尾找第一个出现不协调的地方,即前面比后面大,然后再往前找和这个数相同的位,更新不协调位,因为当前位-1后,如果上一个数和当前数相同,会出现新的不协调,把不协调位的值-1,然后把它后面的位都置9
解法二:
从尾到头取数据,如果当前位比前一位大,则当前位乘以权值-1(相当于当前位-1,后面所有位指9)替换目标值,否则就把当前位乘以权值加到目标值,重复这个过程,直到遍历完。
这个写的实在是太漂亮了,虽然我一开始也想了直接用Int来解决,但是觉得实现起来可能和解法一没什么区别,就是优化一点点,但是这个就写的太漂亮了。
代码
解法一:
1 | public int monotoneIncreasingDigits(int N) { |
解法二:
1 | public int monotoneIncreasingDigits(int N) { |
2020/12/16
题目
给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
1 | 输入: pattern = "abba", str = "dog cat cat dog" |
示例 2:
1 | 输入:pattern = "abba", str = "dog cat cat fish" |
示例 3:
1 | 输入: pattern = "aaaa", str = "dog cat cat dog" |
示例 4:
1 | 输入: pattern = "abba", str = "dog dog dog dog" |
说明:
你可以假设 pattern 只包含小写字母, str 包含了由单个空格分隔的小写字母。
思路
使用两个Map进行双向绑定,单向绑定会出问题
代码
1 | public boolean wordPattern(String pattern, String s) { |
2020/12/17
题目
给定一个整数数组 prices,其中第 i 个元素代表了第 i 天的股票价格 ;非负整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
示例 1:
1 | 输入: prices = [1, 3, 2, 8, 4, 9], fee = 2 |
注意:
0 < prices.length <= 50000.0 < prices[i] < 50000.0 <= fee < 50000.
思路
使用dp来维护每个下标的状态:
- 状态0 :当前没有股票,可以从持有股票通过卖掉股票转换来,或者从没有股票转换来。
- 状态1 :当前有股票,可以由继续持有股票转换来,或者当前节点买入股票。
观察发现并不需要一整个数组的dp,每一次更新只用到了上一个节点,所以使用两个变量即可
下面附上没有优化和优化过的代码
代码
1 | // 未优化 |
1 | // 优化 |
2020/12/18
题目
给定两个字符串 s 和 t,它们只包含小写字母。
字符串 t\ 由字符串 s\ 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
示例 1:
1 | 输入:s = "abcd", t = "abcde" |
示例 2:
1 | 输入:s = "", t = "y" |
示例 3:
1 | 输入:s = "a", t = "aa" |
示例 4:
1 | 输入:s = "ae", t = "aea" |
提示:
0 <= s.length <= 1000t.length == s.length + 1s和t只包含小写字母
思路
计数即可
代码
1 | public char findTheDifference(String s, String t) { |
2020/12/19
题目
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在**原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要**使用另一个矩阵来旋转图像。
示例 1:
1 | 给定 matrix = |
示例 2:
1 | 给定 matrix = |
思路
递归+模拟反转,每一次拿最外面的一圈进行交换,然后递归交换里面一圈
代码
1 | // 也可以作为参数传递,这里外提了 |
2020/12/20
题目
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
示例 1:
1 | 输入:s = "bcabc" |
示例 2:
1 | 输入:s = "cbacdcbc" |
提示:
1 <= s.length <= 104s由小写英文字母组成
思路
构建一个栈(双向队列)维护数据。遍历数据,如果当前数据未使用且比栈顶元素小,并且栈顶元素数量多于1,则弹出栈顶元素,重复这个过程直到栈顶元素小于当前元素或者栈为空
代码
1 | public String removeDuplicateLetters(String s) { |
2020/12/21
题目
数组的每个索引作为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始)。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
示例 1:
1 | 输入: cost = [10, 15, 20] |
示例 2:
1 | 输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] |
注意:
cost的长度将会在[2, 1000]。- 每一个
cost[i]将会是一个Integer类型,范围为[0, 999]。
思路
正常dp题,每一个楼梯的累加费用通过前两个楼梯即可求出,返回倒数第二个或者最后一个中费用最小的即可。
代码
1 | public int minCostClimbingStairs(int[] cost) { |
2020/12/22
题目
给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如:
给定二叉树 [3,9,20,null,null,15,7],
1 | 3 |
返回锯齿形层序遍历如下:
1 | [ |
思路
使用一个信号,来确定当前是从头到尾拿数据还是从尾到头拿数据,数据结构选择双向队列。
代码
1 | public List<List<Integer>> zigzagLevelOrder(TreeNode root) { |
2020/12/23
题目
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:
1 | s = "leetcode" |
提示:你可以假定该字符串只包含小写字母。
思路
从头到尾遍历数组,如果当前字符没有查询过,则从尾到头查询相同字符,查询结果如果和当前字符的下标相同,则表示只有一个,返回下标,如果遍历结束没有返回,则表示没有单一字符,返回-1
代码
1 | public int firstUniqChar(String s) { |
2020/12/24
题目
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
- 每个孩子至少分配到 1 个糖果。
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
1 | 输入: [1,0,2] |
示例 2:
1 | 输入: [1,2,2] |
思路
从左到右遍历数据,如果当前数据的等级比前一个高,则当前分为糖果为前一个数据的糖果数+1,更新当前数据后,从这个位置向前更新数据,因为当前位置的更新,可能导致之前数据分配不对。
此方法可以进行优化,没必要每一次分配糖果都更新前面的数据,可以等遍历完,再完整的进行一次更新即可
代码
未优化
1 | public int candy(int[] ratings) { |
优化
1 | public int candy(int[] ratings) { |
2020/12/25
题目
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
1 | 输入: g = [1,2,3], s = [1,1] |
示例 2:
1 | 输入: g = [1,2], s = [1,2,3] |
提示:
1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1
思路
排序后贪心,将最大的饼干给当前队列胃口最大的孩子总不会有错
代码
1 | public int findContentChildren(int[] g, int[] s) { |
2020/12/26
题目
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:

1 | 输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]] |
示例 2:
1 | 输入:matrix = [] |
示例 3:
1 | 输入:matrix = [["0"]] |
示例 4:
1 | 输入:matrix = [["1"]] |
示例 5:
1 | 输入:matrix = [["0","0"]] |
提示:
rows == matrix.lengthcols == matrix[0].length0 <= row, cols <= 200matrix[i][j]为'0'或'1'
思路
我无思路,具体思路看题解
代码
1 | public int maximalRectangle(char[][] matrix) { |
2020/12/27
题目
给定两个字符串 s 和 t\,判断它们是否是同构的。
如果 s 中的字符可以被替换得到 t\ ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
示例 1:
1 | 输入: s = "egg", t = "add" |
示例 2:
1 | 输入: s = "foo", t = "bar" |
示例 3:
1 | 输入: s = "paper", t = "title" |
说明:
你可以假设 s 和 t 具有相同的长度。
思路
这道题其实就是问 s 和 t 的字符结构要匹配,给每个字符映射一个数字,然后根据这个数字来算出当前字符串的模式值(自己定义的一个概念,即由于每个字符都对应一个数字,所以可以根据这些数字算出一个可能是每个结构都唯一的值),计算方法如代码所示,接着只需要比较这个模式值就可以了。
代码
1 | public boolean isIsomorphic(String s, String t) { |
2020/12/28
题目
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
1 | 输入:k = 2, prices = [2,4,1] |
示例 2:
1 | 输入:k = 2, prices = [3,2,6,5,0,3] |
提示:
0 <= k <= 1090 <= prices.length <= 10000 <= prices[i] <= 1000
思路
使用DP,就是再加一维数组来标记股票的购买数,具体看题解(我也是看题解的)
代码
1 | public int maxProfit(int k, int[] prices) { |
2020/12/29
题目
给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
1 | 输入: nums = [1,3], n = 6 |
示例 2:
1 | 输入: nums = [1,5,10], n = 20 |
示例 3:
1 | 输入: nums = [1,2,2], n = 5 |
思路
对于正整数 xx,如果区间 [1,x−1] 内的所有数字都已经被覆盖,且 xx 在数组中,则区间 [1,2x-1] 内的所有数字也都被覆盖。证明如下。
对于任意 1 <= y < x,y 已经被覆盖,x 在数组中,因此 y+x 也被覆盖,区间 [x+1,2x-1](即区间 [1,x−1] 内的每个数字加上 x 之后得到的区间)内的所有数字也被覆盖,由此可得区间 [1,2x−1] 内的所有数字都被覆盖。
使用贪心算法,每一次填充一个最小的缺少的值,假如填充的数为3,则2 * 3 - 1 = 5,这个范围的数就都填充完毕,证明如上。
代码
1 | public int minPatches(int[] nums, int n) { |
2020/12/30
题目
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
- 如果
x == y,那么两块石头都会被完全粉碎; - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
1 | 输入:[2,7,4,1,8,1] |
提示:
1 <= stones.length <= 301 <= stones[i] <= 1000
思路
使用一个优先队列维护,然后每一次从队首拿出两个元素,相减以后,如果不为0则加回队列,重复此步骤,直到队列的长度小于等于1
代码
1 | public int lastStoneWeight(int[] stones) { |
2020/12/31
题目
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意:
- 可以认为区间的终点总是大于它的起点。
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
1 | 输入: [ [1,2], [2,3], [3,4], [1,3] ] |
示例 2:
1 | 输入: [ [1,2], [1,2], [1,2] ] |
示例 3:
1 | 输入: [ [1,2], [2,3] ] |
思路
贪心思想,按最早的结束位置对数组进行排序,然后遍历数组,如果当前数组可以拼接上上一个则留下,否则抛弃。
代码
1 | public int eraseOverlapIntervals(int[][] intervals) { |
2021/1/1
题目
假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 朵花?能则返回True,不能则返回False。
示例 1:
1 | 输入: flowerbed = [1,0,0,0,1], n = 1 |
示例 2:
1 | 输入: flowerbed = [1,0,0,0,1], n = 2 |
注意:
- 数组内已种好的花不会违反种植规则。
- 输入的数组长度范围为 [1, 20000]。
- n 是非负整数,且不会超过输入数组的大小。
思路
贪心思路,根据上一个判断当前是否能种花,能种直接种,但是有一些花是之前就存在的,所以如果遍历到已经存在的话,则看一下上一个是不是花,是的话直接拔了。
0 0 0 1 -> 1 0 1 1 -> 1 0 0 1
0 0 0 1 -> 0 1 0 1
此贪心是最优的
代码
1 | public boolean canPlaceFlowers(int[] flowerbed, int n) { |
2021/1/2
题目
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
示例 1:
1 | 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 |
示例 2:
1 | 输入:nums = [1], k = 1 |
示例 3:
1 | 输入:nums = [1,-1], k = 1 |
示例 4:
1 | 输入:nums = [9,11], k = 2 |
示例 5:
1 | 输入:nums = [4,-2], k = 2 |
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 1041 <= k <= nums.length
思路
我自己的做法挂了,暴力加剪枝,果然挂了,下面讲的是题解的算法。
解法一:优先队列
使用优先队列存储最大值,每一次滑动只需要在队首拿数据即可,我一开始也想到了优先队列,但是不知道删除的时机,所以不知道怎么写,其实不用急着删除,只需要保证队首的元素是在滑动窗口内就可以。
解法二:单调队列
如果窗口里面有a,b两个元素,a的下标比b小且值也比b小,这就意味着a用于不会有成为最大值的情况,因为窗口是从左到右移动的,如果a在窗口内则b也在窗口内。
所以我们可以构建一个单调队列来存储数据,单调队列内,元素的值是递减的,下标是递增的,可以从队首拿出滑动窗口的最大值。
当添加数据时,逐步弹出下标比它小并且值比它小的队列元素,拿出队首元素的时候,需要判断是否在滑动窗口内。
代码
优先队列
1 | public int[] maxSlidingWindow(int[] nums, int k) { |
单调队列
1 | public int[] maxSlidingWindow(int[] nums, int k) { |
2021/1/3
题目
给你一个链表和一个特定值 x ,请你对链表进行分隔,使得所有小于 x 的节点都出现在大于或等于 x 的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
示例:
1 | 输入:head = 1->4->3->2->5->2, x = 3 |
思路
创建两个链表分别存储小于 x 和大于等于 x 的节点,然后拼接链表就可以了
代码
1 | public ListNode partition(ListNode head, int x) { |
2021/1/4
题目
斐波那契数,通常用 F(n) 表示,形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
1 | F(0) = 0,F(1) = 1 |
给你 n ,请计算 F(n) 。
示例 1:
1 | 输入:2 |
示例 2:
1 | 输入:3 |
示例 3:
1 | 输入:4 |
提示:
0 <= n <= 30
思路
斐波那契就没什么好说的,保留两个数即可
代码
1 | public int fib(int n) { |
2021/1/5
题目
在一个由小写字母构成的字符串 s 中,包含由一些连续的相同字符所构成的分组。
例如,在字符串 s = "abbxxxxzyy" 中,就含有 "a", "bb", "xxxx", "z" 和 "yy" 这样的一些分组。
分组可以用区间 [start, end] 表示,其中 start 和 end 分别表示该分组的起始和终止位置的下标。上例中的 "xxxx" 分组用区间表示为 [3,6] 。
我们称所有包含大于或等于三个连续字符的分组为 较大分组 。
找到每一个 较大分组 的区间,按起始位置下标递增顺序排序后,返回结果。
示例 1:
1 | 输入:s = "abbxxxxzzy" |
示例 2:
1 | 输入:s = "abc" |
示例 3:
1 | 输入:s = "abcdddeeeeaabbbcd" |
示例 4:
1 | 输入:s = "aba" |
提示:
1 <= s.length <= 1000s仅含小写英文字母
思路
很简单的题,就遍历,然后看看连续的字符数量是否大于3,如果大于3就加入。
提交以后发现空间复杂度不是很理想,我想我也没用几个东西啊,然后就换一种方法,换成双指针,提交上去发现也差不了多少。然后才想起来,力扣的提交,时间和空间是有误差的,由于数据小,误差有时候就很明显。
这里把两份代码都贴上来吧,虽然两份代码性能都差不多,但是双指针的比较直观好理解
代码
正常解法
1 | // 正常遍历 |
双指针
1 | // 双指针 |
2021/1/6
题目
给你一个变量对数组 equations 和一个实数值数组 values 作为已知条件,其中 equations[i] = [Ai, Bi] 和 values[i] 共同表示等式 Ai / Bi = values[i] 。每个 Ai 或 Bi 是一个表示单个变量的字符串。
另有一些以数组 queries 表示的问题,其中 queries[j] = [Cj, Dj] 表示第 j 个问题,请你根据已知条件找出 Cj / Dj = ? 的结果作为答案。
返回 所有问题的答案 。如果存在某个无法确定的答案,则用 -1.0 替代这个答案。
注意:输入总是有效的。你可以假设除法运算中不会出现除数为 0 的情况,且不存在任何矛盾的结果。
示例 1:
1 | 输入:equations = [["a","b"],["b","c"]], values = [2.0,3.0], queries = [["a","c"],["b","a"],["a","e"],["a","a"],["x","x"]] |
示例 2:
1 | 输入:equations = [["a","b"],["b","c"],["bc","cd"]], values = [1.5,2.5,5.0], queries = [["a","c"],["c","b"],["bc","cd"],["cd","bc"]] |
示例 3:
1 | 输入:equations = [["a","b"]], values = [0.5], queries = [["a","b"],["b","a"],["a","c"],["x","y"]] |
提示:
1 <= equations.length <= 20equations[i].length == 21 <= Ai.length, Bi.length <= 5values.length == equations.length0.0 < values[i] <= 20.01 <= queries.length <= 20queries[i].length == 21 <= Cj.length, Dj.length <= 5Ai, Bi, Cj, Dj由小写英文字母与数字组成
思路
我自己的思路是模拟,假如a / b = 2,则设置 a = 2x1,b = x1,x1是一个组别,为了处理数据出来的先后而设置的,比如 a / b = 2,c / d = 2,a / c = 2,如果一开始设置 a = 2,b = 1,c = 2,d = 1,那 a / c 就矛盾了,如果按我的方法,a = 2x1,b = 1x1,c = 2x2,d = 1x2,只需要在再搭建一个x1 到 x2 的桥梁即可。
如果两个节点都没有组别,则创建一个新的组别给他们,如果其中一个有组别了,则使用这个组别给另外一个赋值,如果都有组别则搭建一个组别之间的桥梁,这样就把所有的关系连接起来了。
判别的时候
- 如果问题数据两个都不存在组别则输出-1.0
- 两个结点相等就输出1.0(这一步判定需要放在上一步后面)
- 否则拿出各自组别,然后判断组别是否相等
- 相等的话,直接值相除
- 否则,拿出桥梁,通过桥梁计算
题解的思路更加清晰,把各个结点连接成一个图,然后通过图来计算点到点的距离,好久没遇到图的题目了,一时间没想起这种做法
看是中等题,做是困难题,题解中等题
代码
模拟
1 | public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) { |
题解,图 + Floyd
1 | public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) { |
2021/1/7
题目
难度中等398收藏分享切换为英文接收动态反馈
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例 1:
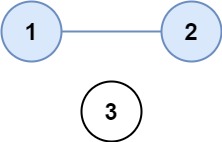
1 | 输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] |
示例 2:
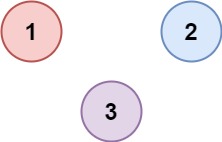
1 | 输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] |
提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
思路
遍历每个没有遍历过的节点,遍历节点的时候,把所有相关的都遍历一遍,就是深搜啦,深搜的次数就是答案
代码
1 | // 全局变量 |
2021/1/8
题目
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
进阶:
- 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
- 你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
示例 1:
1 | 输入: nums = [1,2,3,4,5,6,7], k = 3 |
示例 2:
1 | 输入:nums = [-1,-100,3,99], k = 2 |
提示:
1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 10 <= k <= 105
思路
将向左转换为向右,然后数组移位即可
代码
1 | public void rotate(int[] nums, int k) { |
2021/1/9
题目
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
1 | 输入:prices = [3,3,5,0,0,3,1,4] |
示例 2:
1 | 输入:prices = [1,2,3,4,5] |
示例 3:
1 | 输入:prices = [7,6,4,3,1] |
示例 4:
1 | 输入:prices = [1] |
提示:
1 <= prices.length <= 1050 <= prices[i] <= 105
思路
维护四个状态
- 第一次进行股票购买, buy1
- 第一次进行股票出售, buy2
- 第二次进行股票购买, sell1
- 第二次进行股票出售, sell2
由于不限制当天买入当天卖出,所以对于[1,2,3,4,5,6]也没有影响
三言两语解释不是很清楚,还是看题解吧。
代码
1 | // 题目并不限制在一天之内买入并卖出 |
2021/1/10
题目
给定一个无重复元素的有序整数数组 nums 。
返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
列表中的每个区间范围 [a,b] 应该按如下格式输出:
"a->b",如果a != b"a",如果a == b
示例 1:
1 | 输入:nums = [0,1,2,4,5,7] |
示例 2:
1 | 输入:nums = [0,2,3,4,6,8,9] |
示例 3:
1 | 输入:nums = [] |
示例 4:
1 | 输入:nums = [-1] |
示例 5:
1 | 输入:nums = [0] |
提示:
0 <= nums.length <= 20-231 <= nums[i] <= 231 - 1nums中的所有值都 互不相同nums按升序排列
思路
双指针遍历,即可,只要前一个的数据比当前大1,则第二个指针自增1,其实单指针就行了,第一个指针没什么用处,
代码
1 | public List<String> summaryRanges(int[] nums) { |
2021/1/11
题目
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
示例 1:
1 | 输入:s = "dcab", pairs = [[0,3],[1,2]] |
示例 2:
1 | 输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]] |
示例 3:
1 | 输入:s = "cba", pairs = [[0,1],[1,2]] |
提示:
1 <= s.length <= 10^50 <= pairs.length <= 10^50 <= pairs[i][0], pairs[i][1] < s.lengths中只含有小写英文字母
思路
唉,周赛的题还是绕不过去,这题和周赛的差不多,就是简单一些。思路如下,
只要两个节点能相互交换就将他们放在同一个联通子集中,然后给每一个联通子集一个优先队列,用来弹出最小的字符。
代码
1 | public class LC1202 { |
2021/1/12
题目
公司共有 n 个项目和 m 个小组,每个项目要不无人接手,要不就由 m 个小组之一负责。
group[i] 表示第 i 个项目所属的小组,如果这个项目目前无人接手,那么 group[i] 就等于 -1。(项目和小组都是从零开始编号的)小组可能存在没有接手任何项目的情况。
请你帮忙按要求安排这些项目的进度,并返回排序后的项目列表:
- 同一小组的项目,排序后在列表中彼此相邻。
- 项目之间存在一定的依赖关系,我们用一个列表
beforeItems来表示,其中beforeItems[i]表示在进行第i个项目前(位于第i个项目左侧)应该完成的所有项目。
如果存在多个解决方案,只需要返回其中任意一个即可。如果没有合适的解决方案,就请返回一个 空列表 。
示例 1:
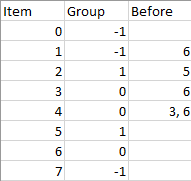
1 | 输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3,6],[],[],[]] |
示例 2:
1 | 输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3],[],[4],[]] |
提示:
1 <= m <= n <= 3 * 104group.length == beforeItems.length == n-1 <= group[i] <= m - 10 <= beforeItems[i].length <= n - 10 <= beforeItems[i][j] <= n - 1i != beforeItems[i][j]beforeItems[i]不含重复元素
思路
无思路,今天这道题是真的不会,可以去期末复习了
代码
题解代码
1 | class Solution { |
2021/1/13
题目
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例 1:
1 | 输入: [[1,2], [1,3], [2,3]] |
示例 2:
1 | 输入: [[1,2], [2,3], [3,4], [1,4], [1,5]] |
注意:
- 输入的二维数组大小在 3 到 1000。
- 二维数组中的整数在1到N之间,其中N是输入数组的大小。
思路
继续用昨天并查集做,遍历每个节点对并查找他们的源节点,如果源节点相同,则代表它们在之前就连接过了,再加入会导致环,把他们当成答案返回,否则就连接两个节点,题目保证会产生环,所以不用其他处理。
我觉得有点问题
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边
[u, v]应满足相同的格式u < v
但是我代码写的是先出现先返回,还是过了,如果要返回最后一个,得把所有会产生环的边存起来再返回最后一个。
代码
并查集的代码和昨天一样,就不贴了
1 | public int[] findRedundantConnection(int[][] edges) { |
2021/1/14
题目
给定由若干 0 和 1 组成的数组 A。我们定义 N_i:从 A[0] 到 A[i] 的第 i 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
返回布尔值列表 answer,只有当 N_i 可以被 5 整除时,答案 answer[i] 为 true,否则为 false。
示例 1:
1 | 输入:[0,1,1] |
示例 2:
1 | 输入:[1,1,1] |
示例 3:
1 | 输入:[0,1,1,1,1,1] |
示例 4:
1 | 输入:[1,1,1,0,1] |
提示:
1 <= A.length <= 30000A[i]为0或1
思路
从头遍历到尾,计算出前面当前二进制的值即可,注意,每一次计算机的模5,5比较特殊,可以这么计算,不然总值会超出长度
代码
1 | public List<Boolean> prefixesDivBy5(int[] A) { |
2021/1/15(欠)
题目
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。
示例 1:
1 | 输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]] |
示例 2:
1 | 输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]] |
示例 3:
1 | 输入:stones = [[0,0]] |
提示:
1 <= stones.length <= 10000 <= xi, yi <= 104- 不会有两块石头放在同一个坐标点上
思路
要考试了,今天暂时鸽了,cv题解的,考完试回来补上,后面几天应该也是一样
好了回来补上了!
这道题其实是问有多少个连通分支的,在同一个纵坐标和横坐标算同一个联通分支,因为相同的联通分支总是能拿剩一个。
现在的问题是,如何把x和y对应起来,因为题目限制的横竖坐标长度为10000,因此,可以把x映射到10001-20000,这样就把横竖坐标降为一维了。
代码
1 | import java.util.HashMap; |
2021/1/16(欠)
题目
有一个 m x n 的二元网格,其中 1 表示砖块,0 表示空白。砖块 稳定(不会掉落)的前提是:
- 一块砖直接连接到网格的顶部,或者
- 至少有一块相邻(4 个方向之一)砖块 稳定 不会掉落时
给你一个数组 hits ,这是需要依次消除砖块的位置。每当消除 hits[i] = (rowi, coli) 位置上的砖块时,对应位置的砖块(若存在)会消失,然后其他的砖块可能因为这一消除操作而掉落。一旦砖块掉落,它会立即从网格中消失(即,它不会落在其他稳定的砖块上)。
返回一个数组 result ,其中 result[i] 表示第 i 次消除操作对应掉落的砖块数目。
注意,消除可能指向是没有砖块的空白位置,如果发生这种情况,则没有砖块掉落。
示例 1:
1 | 输入:grid = [[1,0,0,0],[1,1,1,0]], hits = [[1,0]] |
示例 2:
1 | 输入:grid = [[1,0,0,0],[1,1,0,0]], hits = [[1,1],[1,0]] |
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 200grid[i][j]为0或11 <= hits.length <= 4 * 104hits[i].length == 20 <= xi <= m - 10 <= yi <= n - 1- 所有
(xi, yi)互不相同
思路
今天依旧余着
这道题补不动,下一题。。。
代码
1 | public class Solution { |
2021/1/17(欠)
题目
在一个 XY 坐标系中有一些点,我们用数组 coordinates 来分别记录它们的坐标,其中 coordinates[i] = [x, y] 表示横坐标为 x、纵坐标为 y 的点。
请你来判断,这些点是否在该坐标系中属于同一条直线上,是则返回 true,否则请返回 false。
示例 1:
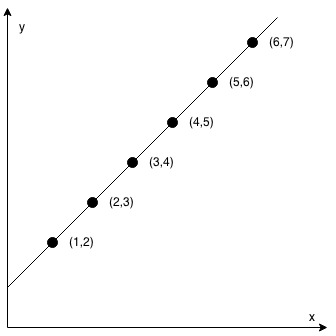
1 | 输入:coordinates = [[1,2],[2,3],[3,4],[4,5],[5,6],[6,7]] |
示例 2:
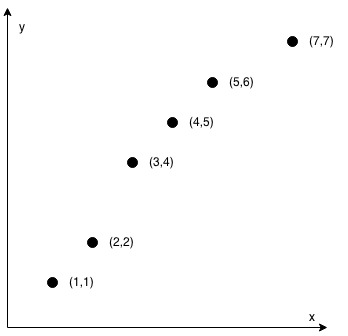
1 | 输入:coordinates = [[1,1],[2,2],[3,4],[4,5],[5,6],[7,7]] |
提示:
2 <= coordinates.length <= 1000coordinates[i].length == 2-10^4 <= coordinates[i][0], coordinates[i][1] <= 10^4coordinates中不含重复的点
思路
考试
来补了
简单题,简单做
通过斜率来判断是否相等
记得处理一下竖线和横线的情况就好了
代码
1 | public boolean checkStraightLine(int[][] coordinates) { |
我的代码
1 | public boolean checkStraightLine(int[][] coordinates) { |
2021/1/18(欠)
题目
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name)*,其余元素是 *emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。账户本身可以以任意顺序返回。
示例 1:
1 | 输入: |
提示:
accounts的长度将在[1,1000]的范围内。accounts[i]的长度将在[1,10]的范围内。accounts[i][j]的长度将在[1,30]的范围内。
思路
考试
代码
1 | public List<List<String>> accountsMerge(List<List<String>> accounts) { |
2021/1/19(补)
题目
难度中等118收藏分享切换为英文接收动态反馈
给你一个points 数组,表示 2D 平面上的一些点,其中 points[i] = [xi, yi] 。
连接点 [xi, yi] 和点 [xj, yj] 的费用为它们之间的 曼哈顿距离 :|xi - xj| + |yi - yj| ,其中 |val| 表示 val 的绝对值。
请你返回将所有点连接的最小总费用。只有任意两点之间 有且仅有 一条简单路径时,才认为所有点都已连接。
示例 1:
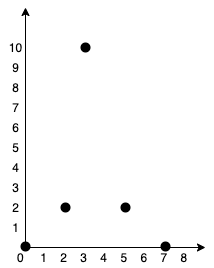
1 | 输入:points = [[0,0],[2,2],[3,10],[5,2],[7,0]] |
示例 2:
1 | 输入:points = [[3,12],[-2,5],[-4,1]] |
示例 3:
1 | 输入:points = [[0,0],[1,1],[1,0],[-1,1]] |
示例 4:
1 | 输入:points = [[-1000000,-1000000],[1000000,1000000]] |
示例 5:
1 | 输入:points = [[0,0]] |
提示:
1 <= points.length <= 1000-106 <= xi, yi <= 106- 所有点
(xi, yi)两两不同。
思路
实在是没时间,我连cv都忘了,暂时先补上,后面一起处理
代码
1 | class Solution { |
2021/1/20
题目
难度简单254收藏分享切换为英文接收动态反馈
给定一个整型数组,在数组中找出由三个数组成的最大乘积,并输出这个乘积。
示例 1:
1 | 输入: [1,2,3] |
示例 2:
1 | 输入: [1,2,3,4] |
注意:
- 给定的整型数组长度范围是[3,104],数组中所有的元素范围是[-1000, 1000]。
- 输入的数组中任意三个数的乘积不会超出32位有符号整数的范围。
思路
这题太简单,看一下就知道了,要么都是最大,要么两个最小一个最大,第一次没注意有负数错了
代码
1 | public int maximumProduct(int[] nums) { |
2021/1/24
题目
给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。
连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], ..., nums[r - 1], nums[r]] 就是连续递增子序列。
示例 1:
1 | 输入:nums = [1,3,5,4,7] |
示例 2:
1 | 输入:nums = [2,2,2,2,2] |
提示:
0 <= nums.length <= 104-109 <= nums[i] <= 109
思路
遍历数组,通过和上一个数字比较,如果大于,就长度加一,否则长度置1,然后保存最长的即可。
代码
1 | public int findLengthOfLCIS(int[] nums) { |
额外
抱歉,这阵子有点没顾过来(cv都忘了),今天开始正式回到日常,以及开始补之前的题,唉,可惜本月的徽章没了
2021/1/25
题目
在由 1 x 1 方格组成的 N x N 网格 grid 中,每个 1 x 1 方块由 /、\ 或空格构成。这些字符会将方块划分为一些共边的区域。
(请注意,反斜杠字符是转义的,因此 \ 用 "\\" 表示。)。
返回区域的数目。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
示例 3:
1 | 输入: |
示例 4:
1 | 输入: |
示例 5:
1 | 输入: |
提示:
1 <= grid.length == grid[0].length <= 30grid[i][j]是'/'、'\'、或' '。
思路
今天的题很奇怪,不想搞这种,代码是题解的
代码
1 | public int regionsBySlashes(String[] grid) { |
2021/1/26
题目
给你一个由一些多米诺骨牌组成的列表 dominoes。
如果其中某一张多米诺骨牌可以通过旋转 0 度或 180 度得到另一张多米诺骨牌,我们就认为这两张牌是等价的。
形式上,dominoes[i] = [a, b] 和 dominoes[j] = [c, d] 等价的前提是 a==c 且 b==d,或是 a==d 且 b==c。
在 0 <= i < j < dominoes.length 的前提下,找出满足 dominoes[i] 和 dominoes[j] 等价的骨牌对 (i, j) 的数量。
示例:
1 | 输入:dominoes = [[1,2],[2,1],[3,4],[5,6]] |
提示:
1 <= dominoes.length <= 400001 <= dominoes[i][j] <= 9
思路
第一眼的思路是两个for循环,然后优化一下是先进行两次两次排序,然后再遍历。
但是因为这道题数字值很小很小,也就是可以把二维映射成为一维,然后取值即可
代码
自己的两次遍历
1 | public int numEquivDominoPairs(int[][] dominoes) { |
题解降维
1 | public int numEquivDominoPairs(int[][] dominoes) { |
2021/1/27
题目
Alice 和 Bob 共有一个无向图,其中包含 n 个节点和 3 种类型的边:
- 类型 1:只能由 Alice 遍历。
- 类型 2:只能由 Bob 遍历。
- 类型 3:Alice 和 Bob 都可以遍历。
给你一个数组 edges ,其中 edges[i] = [typei, ui, vi] 表示节点 ui 和 vi 之间存在类型为 typei 的双向边。请你在保证图仍能够被 Alice和 Bob 完全遍历的前提下,找出可以删除的最大边数。如果从任何节点开始,Alice 和 Bob 都可以到达所有其他节点,则认为图是可以完全遍历的。
返回可以删除的最大边数,如果 Alice 和 Bob 无法完全遍历图,则返回 -1 。
示例 1:
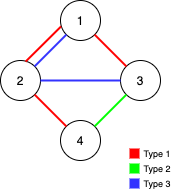
1 | 输入:n = 4, edges = [[3,1,2],[3,2,3],[1,1,3],[1,2,4],[1,1,2],[2,3,4]] |
示例 2:
1 | 输入:n = 4, edges = [[3,1,2],[3,2,3],[1,1,4],[2,1,4]] |
示例 3:
1 | 输入:n = 4, edges = [[3,2,3],[1,1,2],[2,3,4]] |
提示:
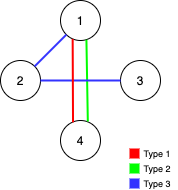
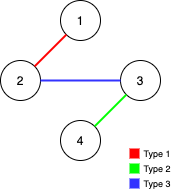
1 <= n <= 10^51 <= edges.length <= min(10^5, 3 * n * (n-1) / 2)edges[i].length == 31 <= edges[i][0] <= 31 <= edges[i][1] < edges[i][2] <= n- 所有元组
(typei, ui, vi)互不相同
思路
使用两个并查集,先使用公共边(双向边)来更新两个并查集,然后使用单向变更新各自的并查集,最后如果各自的连通分支都只有1,则代表可以各自连通,返回删除的边的数目。
更新时候的规则如下:
- 如果两个边不属于同一个连通分支,合并后并查集分支-1
- 如果两个边属于同一连通分支,则删掉这条边,删除的数目+1
代码
1 | import java.util.Arrays; |
2021/1/28
题目
给定一个整数类型的数组 nums,请编写一个能够返回数组 “中心索引” 的方法。
我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
说明:
nums的长度范围为[0, 10000]。- 任何一个
nums[i]将会是一个范围在[-1000, 1000]的整数。
思路
先计算总的和,然后遍历数组,总和逐渐减去当前值,前部分和逐渐加上中间值,然后比较两者,比较要在总和减去之后,前部分和加上之前。
代码
1 | public int pivotIndex(int[] nums) { |
2021/1/29
题目
你准备参加一场远足活动。给你一个二维 rows x columns 的地图 heights ,其中 heights[row][col] 表示格子 (row, col) 的高度。一开始你在最左上角的格子 (0, 0) ,且你希望去最右下角的格子 (rows-1, columns-1) (注意下标从 0 开始编号)。你每次可以往 上,下,左,右 四个方向之一移动,你想要找到耗费 体力 最小的一条路径。
一条路径耗费的 体力值 是路径上相邻格子之间 高度差绝对值 的 最大值 决定的。
请你返回从左上角走到右下角的最小 体力消耗值 。
示例 1:
1 | 输入:heights = [[1,2,2],[3,8,2],[5,3,5]] |
示例 2:
1 | 输入:heights = [[1,2,3],[3,8,4],[5,3,5]] |
示例 3:
1 | 输入:heights = [[1,2,1,1,1],[1,2,1,2,1],[1,2,1,2,1],[1,2,1,2,1],[1,1,1,2,1]] |
提示:
rows == heights.lengthcolumns == heights[i].length1 <= rows, columns <= 1001 <= heights[i][j] <= 106
思路
把二维坐标的点映射成为一维坐标的点,然后,将整个矩阵当成一个图,线的权值为两点的绝对值,然后求左上角到右下角的最短路。
(题解还有其他的,大致看了一下,这个最符合我的思路)
代码
1 | public class LC1631 { |
2021/1/30
题目
在一个 N x N 的坐标方格 grid 中,每一个方格的值 grid[i][j] 表示在位置 (i,j) 的平台高度。
现在开始下雨了。当时间为 t 时,此时雨水导致水池中任意位置的水位为 t 。你可以从一个平台游向四周相邻的任意一个平台,但是前提是此时水位必须同时淹没这两个平台。假定你可以瞬间移动无限距离,也就是默认在方格内部游动是不耗时的。当然,在你游泳的时候你必须待在坐标方格里面。
你从坐标方格的左上平台 (0,0) 出发。最少耗时多久你才能到达坐标方格的右下平台 (N-1, N-1)?
示例 1:
1 | 输入: [[0,2],[1,3]] |
示例2:
1 | 输入: [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]] |
提示:
2 <= N <= 50.grid[i][j]是[0, ..., N*N - 1]的排列。
思路
cv过
代码
1 | public class Solution { |
2021/2/1
题目
爱丽丝和鲍勃有不同大小的糖果棒:A[i] 是爱丽丝拥有的第 i 根糖果棒的大小,B[j] 是鲍勃拥有的第 j 根糖果棒的大小。
因为他们是朋友,所以他们想交换一根糖果棒,这样交换后,他们都有相同的糖果总量。(一个人拥有的糖果总量是他们拥有的糖果棒大小的总和。)
返回一个整数数组 ans,其中 ans[0] 是爱丽丝必须交换的糖果棒的大小,ans[1] 是 Bob 必须交换的糖果棒的大小。
如果有多个答案,你可以返回其中任何一个。保证答案存在。
示例 1:
1 | 输入:A = [1,1], B = [2,2] |
示例 2:
1 | 输入:A = [1,2], B = [2,3] |
示例 3:
1 | 输入:A = [2], B = [1,3] |
示例 4:
1 | 输入:A = [1,2,5], B = [2,4] |
提示:
1 <= A.length <= 100001 <= B.length <= 100001 <= A[i] <= 1000001 <= B[i] <= 100000- 保证爱丽丝与鲍勃的糖果总量不同。
- 答案肯定存在。
思路
求两个数组的和,得到差值,使用Hash存储其中一个数组,然后遍历另一个数组,查看是否有弥补差值的数
代码
1 | public int[] fairCandySwap(int[] A, int[] B) { |
2021/2/2
题目
给你一个仅由大写英文字母组成的字符串,你可以将任意位置上的字符替换成另外的字符,总共可最多替换 k 次。在执行上述操作后,找到包含重复字母的最长子串的长度。
注意:字符串长度 和 k 不会超过 104。
示例 1:
1 | 输入:s = "ABAB", k = 2 |
示例 2:
1 | 输入:s = "AABABBA", k = 1 |
思路
使用滑动窗口来计算最长的长度,窗口的大小不得大于之前最大的元素数量以及k的和。
代码
1 | public int characterReplacement(String s, int k) { |
2021/2/3
题目
中位数是有序序列最中间的那个数。如果序列的大小是偶数,则没有最中间的数;此时中位数是最中间的两个数的平均数。
例如:
[2,3,4],中位数是3[2,3],中位数是(2 + 3) / 2 = 2.5
给你一个数组 nums,有一个大小为 k 的窗口从最左端滑动到最右端。窗口中有 k 个数,每次窗口向右移动 1 位。你的任务是找出每次窗口移动后得到的新窗口中元素的中位数,并输出由它们组成的数组。
示例:
给出 nums = [1,3,-1,-3,5,3,6,7],以及 k = 3。
1 | 窗口位置 中位数 |
因此,返回该滑动窗口的中位数数组 [1,-1,-1,3,5,6]。
提示:
- 你可以假设
k始终有效,即:k始终小于输入的非空数组的元素个数。 - 与真实值误差在
10 ^ -5以内的答案将被视作正确答案。
思路
我真不会
代码
1 | class Solution { |
2021/2/24
题目
难度简单229收藏分享切换为英文接收动态反馈
给定一个二进制矩阵 A,我们想先水平翻转图像,然后反转图像并返回结果。
水平翻转图片就是将图片的每一行都进行翻转,即逆序。例如,水平翻转 [1, 1, 0] 的结果是 [0, 1, 1]。
反转图片的意思是图片中的 0 全部被 1 替换, 1 全部被 0 替换。例如,反转 [0, 1, 1] 的结果是 [1, 0, 0]。
示例 1:
1 | 输入:[[1,1,0],[1,0,1],[0,0,0]] |
示例 2:
1 | 输入:[[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]] |
提示:
1 <= A.length = A[0].length <= 200 <= A[i][j] <= 1
思路
对每一行对象交换,然后在交换的时候反转即可,如何列数是奇数,还需要单独对中间的数进行异或处理。
其实仔细观察题目,可以发现,如果交换的两个数交换之前是不一样的,那么经过交换和反转,其实是没有变化的,可以加上特判,不一样才反转(我的代码里面没有)
代码
1 | public int[][] flipAndInvertImage(int[][] A) { |
额外
好像鸽了好多天,以后会继续回来坚持的,十分抱歉
2021/2/25
题目
难度简单177收藏分享切换为英文接收动态反馈
给你一个二维整数数组 matrix, 返回 matrix 的 转置矩阵 。
矩阵的 转置 是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引。
![]()
示例 1:
1 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]] |
示例 2:
1 | 输入:matrix = [[1,2,3],[4,5,6]] |
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10001 <= m * n <= 105-109 <= matrix[i][j] <= 109
思路
模拟就可以了,竖着从数组拿值,横着放进新数组里面
害我想了很久有没有更好的方法,想不出来,题解也是这种
代码
1 | public int[][] transpose(int[][] matrix) { |
2021/2/26
题目
外国友人仿照中国字谜设计了一个英文版猜字谜小游戏,请你来猜猜看吧。
字谜的迷面 puzzle 按字符串形式给出,如果一个单词 word 符合下面两个条件,那么它就可以算作谜底:
- 单词
word中包含谜面puzzle的第一个字母。 - 单词
word中的每一个字母都可以在谜面puzzle中找到。
例如,如果字谜的谜面是 “abcdefg”,那么可以作为谜底的单词有 “faced”, “cabbage”, 和 “baggage”;而 “beefed”(不含字母 “a”)以及 “based”(其中的 “s” 没有出现在谜面中)都不能作为谜底。
返回一个答案数组 answer,数组中的每个元素 answer[i] 是在给出的单词列表 words 中可以作为字谜迷面 puzzles[i] 所对应的谜底的单词数目。
示例:
1 | 输入: |
提示:
1 <= words.length <= 10^54 <= words[i].length <= 501 <= puzzles.length <= 10^4puzzles[i].length == 7words[i][j],puzzles[i][j]都是小写英文字母。- 每个
puzzles[i]所包含的字符都不重复。
思路
再等我看看
代码
1 | class Solution { |
2021/2/27
题目
给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k 。返回这一子串的长度。
示例 1:
1 | 输入:s = "aaabb", k = 3 |
示例 2:
1 | 输入:s = "ababbc", k = 2 |
提示:
1 <= s.length <= 104s仅由小写英文字母组成1 <= k <= 105
思路
第一种是使用分治 + 递归, 流程如下
- 先计算当前字段每个字符的数量
- 如果所有字符数量都大于 k ,则返回自身长度
- 否则使用字符数量不大于等于 k 的字符进行分割,将分割出来的字段进行自调,返回不同字段中的最大值
这样就可以求出答案了
第二种是使用滑动窗口的方法,在窗口里面维护两个值,分别是,窗口里面字符小于 k 的字符数、窗口里面字符种类的数目,流程如下
- 限定字符的种类 i ,i 从 1 递增至 26
- 向右滑动一个位置
- 如果当前窗口内的字符种类小于 i,则继续滑动右窗口,直到等于 i
- 如果当前窗口内的字符种类大于 i ,则滑动左窗口,直到等于 i
- 如果当前窗口内不存在小于 k 的字符,则将当前长度和已经记录的长度进行比较,取最大值
代码
分治 + 递归
1 | public int longestSubstring(String s, int k) { |
滑动窗口
1 | class Solution { |
2021/2/28
题目
难度简单122收藏分享切换为英文接收动态反馈
如果数组是单调递增或单调递减的,那么它是单调的。
如果对于所有 i <= j,A[i] <= A[j],那么数组 A 是单调递增的。 如果对于所有 i <= j,A[i]> = A[j],那么数组 A 是单调递减的。
当给定的数组 A 是单调数组时返回 true,否则返回 false。
示例 1:
1 | 输入:[1,2,2,3] |
示例 2:
1 | 输入:[6,5,4,4] |
示例 3:
1 | 输入:[1,3,2] |
示例 4:
1 | 输入:[1,2,4,5] |
示例 5:
1 | 输入:[1,1,1] |
提示:
1 <= A.length <= 50000-100000 <= A[i] <= 100000
思路
因为可能是递增或者递减,所以使用一个数字来判断到底是递增递减。
- 先给这个数字 flag 赋值为0,然后遍历数组
- 计算元素差(后一个元素减去前一个)
- 如果是递减的(元素差为负数),查看 flag
- flag 大于 0 ,代表前面出现过递增,返回 false
- 否则给 flag 赋值 1
- 如果是递增的,查看 flag
- flag 小于0,代表前面出现过递减,返回 false
- 否则给 flag 赋值 -1
- 如果相等,不做处理
- 如果是递减的(元素差为负数),查看 flag
这是我一开始的做法,看完题解,觉得题解的更简单明了。使用两个值来判断是否出现递增或者递减,最后返回两个人的或结果。
不过执行的结果是我的运行时间更快,因为我的中间可能就返回结果了
代码
自己的代码(不够直观)
1 | public boolean isMonotonic(int[] A) { |
题解代码
1 | public boolean isMonotonic(int[] A) { |
2021/3/1
题目
难度简单287收藏分享切换为英文接收动态反馈
给定一个整数数组 nums,求出数组从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点。
实现 NumArray 类:
NumArray(int[] nums)使用数组nums初始化对象int sumRange(int i, int j)返回数组nums从索引i到j(i ≤ j)范围内元素的总和,包含i、j两点(也就是sum(nums[i], nums[i + 1], ... , nums[j]))
示例:
1 | 输入: |
提示:
0 <= nums.length <= 104-105 <= nums[i] <= 1050 <= i <= j < nums.length- 最多调用
104次sumRange方法
思路
由于会调用很多次 sumRange ,所以最好每一次能快速算出来,因此计算前缀和,然后每一次就可以用 O(1)的时间算出答案。
这里有一个比较好的设计,就是数组多出一位,这样就不用给特殊情况进行判断了
代码
1 | public class LC303 { |